
That is the setting and I introduce the readers to this setting yesterday, but there was more and there always is. Labels is how we tend to communicate, there is the label of ‘Orange baboon’ there is the label of ‘village idiot’ and there are many more labels. They tend to make life ‘easy’ for us. They are also the hidden trap we introduce to ourselves. In the ‘old’ days we even signify Business Intelligence by this, because it was easy for the people running these things.
And example can be seen in
TABLES
/ v1 v2 v3 v4 v5 BY (LABELS)
/ count.
And we would see the accommodating table with on one side completely agree, agree, neutral, disagree and completely disagree, if that was the 5 point labeling setting we embraced and as such we saw a ‘decently’ complete picture and we all agreed that this was that is had to be.
But the not so hidden snag is that in the first these labels are ordinal (at best) and the setting of Likert scales (their official name) are not set in a scientific way, there is no equally adjusted difference between the number 1,2,3,4,5. That is just the way it is. And in the old days this was OK (as the feeling went). But today in what she call the AI setting and I call it NIP at best, the setting is too dangerous. Now, set this by ‘todays’ standards.
The simple question “Is America bankrupt?” Gets all kinds of answers and some will quite correctly give us “In contrast, the financial health of the United States is relatively healthy within the context of the total value of U.S. assets. A much different picture appears once one looks at the underlying asset base of the private and public economy.” I tend to disagree, but that is me without me economic degrees. But in the AI world it is a simple setting of numbers and America needs Greenland and Canada to continue the retention that “the United States is relatively healthy within the context of the total value of U.S. assets”, yes that would be the setting but without those two places America is likely around bankrupt and the AI bubble will push them over the edge. At least that is how I see it and yesterday I gave one case (or the dozen or so cases that will follow in 2026) in that stage this startup is basically agreeing to a larger then 2 billion settlement. So in what universe does a startup have this money? That is the constriction of AI, and in that setting of unverified and unscaled data the presence gets to be worse. And I remember a answer given to me at a presentation, the answer was “It is what it is” and I kinda accepted it, but an AI will go bonkers and wrong in several ways when that is handed to it. And that is where the setting of AI and NIP (Near Intelligent Parsing) becomes clear. NIP is merely a 90’s chess game that has been taught (trained) every chess game possible and it takes from that setting, but the creative intellect does an illogical move and the chess game loses whatever coherency it has, that move was never programmed and that is where you see the difference between AI and NIP. The AI will creatively adjust its setting, the NIP cannot and that is what will set the stage for all these class actions.
The second setting is ‘human’ error. You see, I placed the Likert scale intentionally, because in between the multitude of 1-5 scales there is one likely variable that was set to 5-1 and the programmers overlooked them and now when you see these AI training grounds at least one variable is set in the wrong direction, tainting the others and massing with the order of the adjusted personal scales. And that is before we get to the result of CLUSTER and QUICKCLUSTER results where a few more issues are introduced to the algorithm of the entire setting and that is where the verification of data becomes imperative and at present.
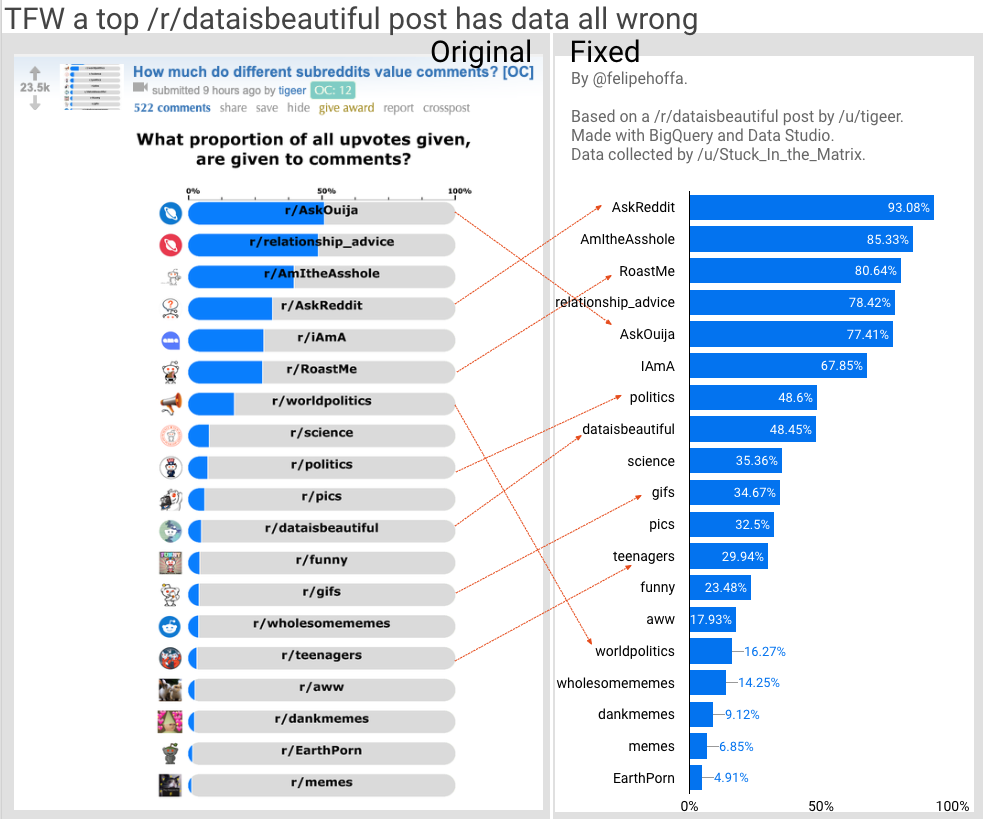
So here is a sort of random image, but the question it needs to raise is what makes these different sources in any way qualified to be a source? In this case if the data is skewed in Ask Reddit, 93% of the data is basically useless and that is missed on a few levels. There are quality high data sources, but these are few and far in-between, in the mean time these sources get to warp any other data we have. And if you are merely looking at legacy data, there is still the Likert scale data you in your own company had and that data is debatable at best.
Labels are dangerous and they are inherently based on the designer of that data source (possible even long dead) and it tends to be done in his of her early stages of employment, making the setting even more debatable as it was ‘influenced’ by greedy CEO’s and CFO’s and they had their bonus in mind. A setting mostly ignored by all involved.
As such are you surprised that I see the AI bubble to what it is? A dangerous reality coming our way in sudden likely unforeseen ways and it is the ‘unforeseen way’ that is the danger, because when these disgruntled employees talk to those who want to win a class action, all kinds of data will come to the surface and that is how these class actions are won.
It was a simple setting I saw coming a mile away and whilst you wandered by I added the Dr. Strange part, you merely thought you had the labels thought through but the setting was a lot more dangerous and it is heading straight to your AI dataset. All wrongly thought through, because training data needs to have something verifiable as ‘absolutely true’ and that is the true setting and to illustrate this we can merely make a stop at Elon Musk inc. Its ‘AI’ grok having the almost prefect setting. We are given from one source “The bot has generated various controversial responses, including conspiracy theories, antisemitism, and praise of Adolf Hitler, as well as referring to Musk’s views when asked about controversial topics or difficult decisions.” Which is almost a dangerous setting towards people fueling Grok in a multitude of ways and ‘Hundreds of thousands of Grok chats exposed in Google results’ (at https://www.bbc.com/news/articles/cdrkmk00jy0o) where we see “The appearance of Grok chats in search engine results was first reported by tech industry publication Forbes, which counted more than 370,000 user conversations on Google. Among chat transcripts seen by the BBC were examples of Musk’s chatbot being asked to create a secure password, provide meal plans for weight loss and answer detailed questions about medical conditions.” Is there anybody willing to do the honors of classifying that data (I absolutely refuse to do so) and I already gave you the headwind in the above story. In the fist how many of these 370,000 users are medical professionals? I think you know where this is going. And I think Grok is pretty neat as a result, but it is not academically useful. At best it is a new form of Wikipedia, at worst it is a round data system (trashcan) and even though it sounds nice, it is as nice as labels can be and that is exactly why these class cases will be decided out of court and as I personally see it when these hit Microsoft and OpenAI will shell over trillions to settle out of court, because the court damage will be infinitely worse. And that is why I see 2026 as the year the graded driven get to start filling to fill their pockets, because the mindful hurt that is brought to court is as academic as a Likert scale, not a scientific setting among them and the pre-AI setting of Mental harm as ““Mental damage” in court refers to psychological injury, such as emotional trauma or psychiatric conditions, that can be the basis for legal claims, either as a plaintiff seeking compensation or as a criminal defendant. In civil cases, plaintiffs may seek damages for mental harm like PTSD, depression, or anxiety if they can prove it was caused by another party’s negligent or wrongful actions, provided it results in a recognizable psychiatric illness.” So as you see it, is this enough or do you want more? Oh, screw that, I need coffee now and I have a busy day ahead, so this is all you get for now.
Have a great day, I am trying to enjoy Thursday, Vancouver is a lot behind me on this effort. So there is a time scale we all have to adhere to (hidden nudge) as such enjoy the day.
