
New York is all up in sixes and sevens, even as they aren’t really confused, some are not seeing the steps that are following and at this point giving $65 billion for 21st Century Fox is not seen in the proper light. You see, Comcast has figured something out, it did so a little late (an assumption), but there is no replacement for experience I reckon. Yet, they are still on time to make the changes and it seems that this is the path they will be walking on. So when we see ‘Comcast launches $65bn bid to steal Murdoch’s Fox away from Disney‘, there are actually two parties to consider. The first one is Disney. Do they realise what they are walking away from? Do they realise the value they are letting go? Perhaps they do and they have decided not to walk that path, which is perfectly valid. The second is the path that Comcast is implied to be walking on. Is it the path that they are planning to hike on, or are they merely setting the path for facilitation and selling it in 6-7 years for no less than 300% of what it is now? Both perfectly valid steps and I wonder which trajectory is planned, because the shift is going to be massive.
To get to this, I will have to admit my own weakness here, because we all have filters and ignoring them is not only folly, it tends to be an anchor that never allows us to go forward. You see, in my view the bulk of the media is a collection of prostitutes. They cater in the first to their shareholders, then there stakeholders and lastly their advertisers. After that, if there are no clashes, the audience is given consideration. That has been the cornerstone of the media for at least 15 years. Media revolves around circulation, revenue and visibility, whatever is left is ‘pro’ reader, this is why you see the public ‘appeal’ to be so emotionally smitten, because when it is about emotion, we look away, we ignore or we agree. That is the setting we all face. So when a step like this is taken, it will be about the shareholders, which grows when the proper stakeholders are found, which now leads to advertising and visibility. Yet, how is this a given and why does it matters? The bottom dollar will forever be profit. Now from a business sense that is not something to argue with, this world can only work on the foundation of profit, we get that, yet newspapers and journalism should be about proper informing the people, and when did that stop? Nearly every paper has investigative journalism, the how many part is more interesting. I personally belief that Andrew Jennings might be one of the last great investigative journalists. It is the other side of the coin that we see ignored, it is the one that matters. The BBC (at https://www.bbc.co.uk/programmes/b06tkl9d) gives us: “Reporter Andrew Jennings has been investigating corruption in world football for the past 15 years“, the question we should ask is how long and how many parties have tried to stop this from becoming public, and how long did it take Andrew Jennings to finally win and this is just ONE issue. How many do not see the light of day? We look at the Microsoft licensing corruption scandal and we think it is a small thing. It is not, it was a lot larger. Here I have a memory that I cannot prove, it was in the newspapers in the Netherlands. On one day there was a small piece regarding the Buma/Stemra and the setting of accountancy reports on the overuse of Microsoft licenses in governments and municipality buildings and something on large penalty fees (it would have been astronomical). Two days later another piece was given that the matter had been resolved. The question becomes was it really? I believe that someone at Microsoft figured out that this was the one moment where on a national level a shift to Linux would have been a logical step, something Microsoft feared very very much. Yet the papers were utterly silent on many levels and true investigation never took place and after the second part, some large emotional piece would have followed.
That is the issue that I have seen and we all have seen these events, we merely wiped it from our minds as other issues mattered more (which is valid). So I have no grate faith (pun intended) into the events of ‘exposure‘ from the media. Here it is not about that part, but the parts that are to come. Comcast has figured out a few things and 21st Century Fox is essential to that. To see that picture, we need to look at another one, so it is a little more transparent. It also shows where IBM, Google, Apple and some telecom companies are tinkering now.
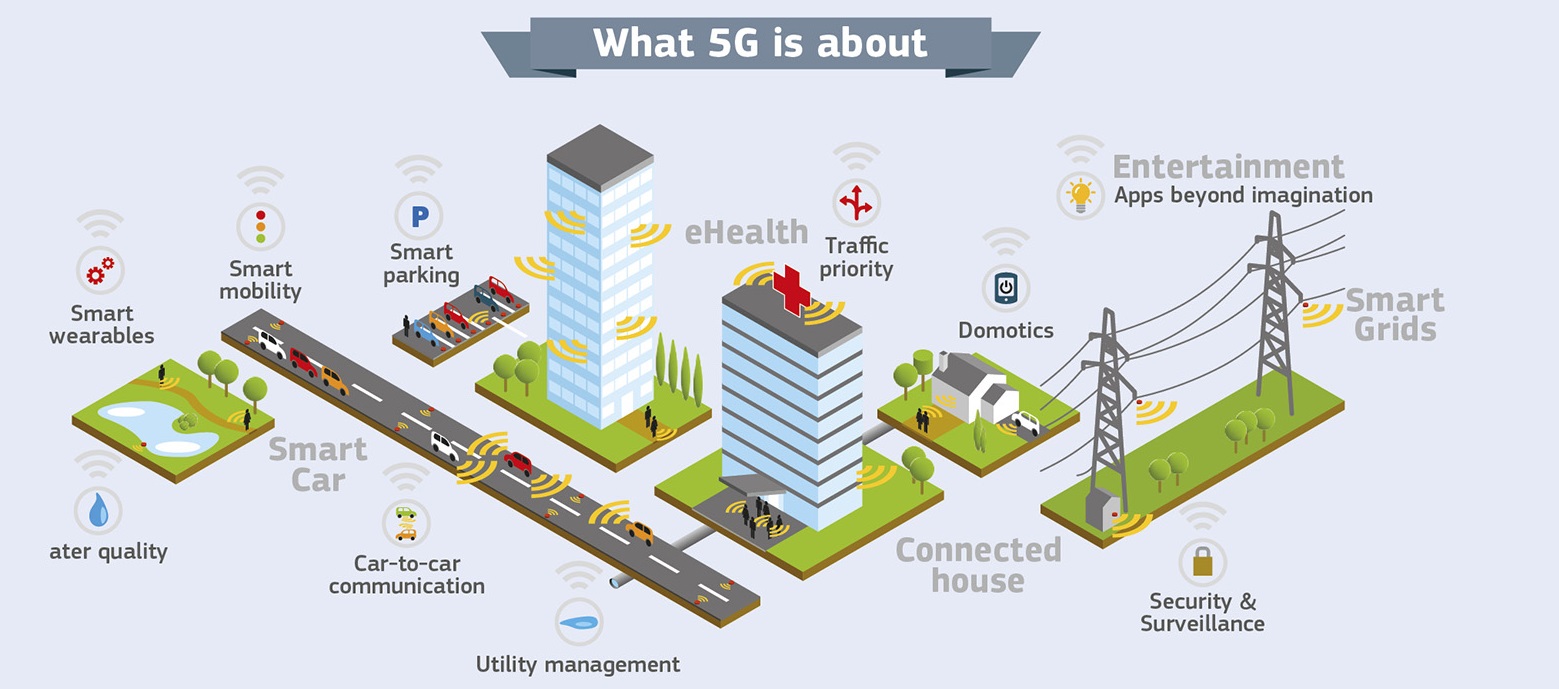 To see this we need to look at this first image and see what there is, it is all tag based, all data and all via mobile and wireless communication. Consider these elements; over 90% of car owners will have them: ‘Smart Mobility, Smart Parking and Traffic priority‘. Now consider the people who are not homeless: ‘Smart grids, Utility management, hose management like smart fridges, smart TV and data based entertainment (Netflix)‘ and all those having smart house devices running on what is currently labelled as Domotics, it adds up to Megabytes of data per household per day. There will be a run on that data from large supermarket to Netflix providers. Now consider the mix between Comcast and 21 Century Fox. Breaking news, new products and new solutions to issues you do not even realise in matters of eHealth, road (traffic) management and the EU set 5G Joint-Declarations in 2015, with Japan, China, Korea and Brazil. The entire Neom setup in Saudi Arabia gives way that they will soon want to join all this, or whoever facilitates for the Middle East and Saudi Arabia will. In all this with all this technology, America is not mentioned, is that not a little too strange? Consider that the given 5G vision is to give ‘Full commercial 5G infrastructure deployment after 2020‘ (expected 2020-2023).
To see this we need to look at this first image and see what there is, it is all tag based, all data and all via mobile and wireless communication. Consider these elements; over 90% of car owners will have them: ‘Smart Mobility, Smart Parking and Traffic priority‘. Now consider the people who are not homeless: ‘Smart grids, Utility management, hose management like smart fridges, smart TV and data based entertainment (Netflix)‘ and all those having smart house devices running on what is currently labelled as Domotics, it adds up to Megabytes of data per household per day. There will be a run on that data from large supermarket to Netflix providers. Now consider the mix between Comcast and 21 Century Fox. Breaking news, new products and new solutions to issues you do not even realise in matters of eHealth, road (traffic) management and the EU set 5G Joint-Declarations in 2015, with Japan, China, Korea and Brazil. The entire Neom setup in Saudi Arabia gives way that they will soon want to join all this, or whoever facilitates for the Middle East and Saudi Arabia will. In all this with all this technology, America is not mentioned, is that not a little too strange? Consider that the given 5G vision is to give ‘Full commercial 5G infrastructure deployment after 2020‘ (expected 2020-2023).
With a 740 million people deployed, and all that data, do you really think the US is not wanting a slice of data that is three times the American population? This is no longer about billions, this will be about trillions, data will become the new corporate and governmental currency and all the larger players want to be on board. So is Disney on the moral high path, or are the requirements just too far from their own business scope? It is perhaps a much older setting that we see when it is about consumer versus supplier. We all want to consume milk, yet most of us are not in a setting where we can be the supplier of milk, having a cow on the 14th floor of an apartment tends to be not too realistic in the end. We might think that it is early days, yet systems like that require large funds and years to get properly set towards the right approach for deployment and implementation. In this an American multinational mass media corporation would fit nicely in getting a chunk of that infrastructure resolved. consider a news media tagging all the watchers on data that passes them by and more importantly the data that they shy away from, it is a founding setting in growing a much larger AI, as every AI is founded on the data it has and more important the evolving data as interaction changes and in this 5G will have close to 20 times the options that 4G has now and in all this we will (for the most) merely blindly accept data used, given and ignored. We saw this earlier this year when we learned that “Facebook’s daily active user base in the U.S. and Canada fell for the first time ever in the fourth quarter, dropping to 184 million from 185 million in the previous quarter“, yet the quarter that followed the usage was back to 185 million users a day. So the people ended up being ‘very’ forgiving, it could be stated that they basically did not care. Knowing this setting where the bump on the largest social media data owner was a mere 0.5405%; how is this path anything but a winning path with an optional foundation of trillions in revenue? There is no way that the US, India, Russia and the commonwealth nations are not part of this. Perhaps not in some 5G Joint-Declarations, but they are there and the one thing Facebook clearly taught them was to be first, and that is what they are all fighting for. The question is who will set the stage by being ahead of schedule with the infrastructure in place and as I see it, Comcast is making an initial open move to get into this field right and quick. Did you think that Google was merely opening 6 data centres, each one large enough to service the European population for close to 10 years? And from the Wall Street journal we got: “Google’s parent company Alphabet is eyeing up a partnership with one of the world’s largest oil companies, Aramco, to aid in the erection of several data centres across the Middle Eastern kingdom“, if one should be large enough to service 2300% of the Saudi Arabian population for a decade, the word ‘several‘ should have been a clear indication that this is about something a lot larger. Did no one catch up on that small little detail?
In that case, I have a lovely bridge for sale, going cheap at $25 million with a great view of Balmain, first come, first serve, and all responsibilities will be transferred to you the new predilector at the moment of payment. #ASuckerIsBornEachMinute
Oh, and this is not me making some ‘this evil Google‘ statement, because they are not. Microsoft, IBM, and several others are all in that race; the AI is merely the front of something a lot larger. Especially when you realise that data in evolution (read: in real-time motion) is the foundation of its optional cognitive abilities. The data that is updated in real-time, that is the missing gem and 5G is the first setting where that is the set reality where it all becomes feasible.
So why would we care? We might not, but we should care because we are the foundation of all that IP and it will no longer be us. It gives value to the users and consumes, whilst those who are not are no longer deemed of any value, that is not the future, it is the near future and the founding steps for this becoming an actual reality is less than 60 months away.
In the end we might have merely cared too late, how is that for the obituary of any individual?
