That is the setting, but that is not what this is about. We are given a setting (at https://www.sbs.com.au/news/article/trump-has-ordered-naval-blockade-of-sanctioned-oil-tankers-in-venezuela-he-says/gcrwrmllu) where we see ‘‘Act of war’: Trump orders blockade of ‘sanctioned’ Venezuela oil tankers’ and we see “But Trump on Tuesday pointed to another goal — regaining US access to Venezuelan oil production. The US armada “will only get bigger,” Trump said, until Venezuela returns “to the United States of America all of the Oil, Land, and other Assets that they previously stole from us.”” But is that true? At what point did Venezuela steal oil from America? Why assets did they steal? What land was stolen? Can we get a clear explanation of that? And if comes with two other settings. The US is pulling out all its troops out of Europe. And in the second setting we see today that one of the most successful American businesses is filing for Bankruptcy. Del Monte originated from California canners in the late 1800s, becoming a household name through the California Packing Corporation (Calpak). It has filed for bankruptcy due to the tariffs on fruits and aluminum. It drove them under in 6 months. And as I see it, a speculated setting is that President Trump will need to sue the BBC, because America is about to lose everything and not one intelligent being will do business with him beginning in 2026.
As I said so before, America is done for and the longer everything is suspended in ‘investigations’ the longer it takes for the America people to see what hardship they are due for, not for a week or a month, but for several years and that is if someone takes over the helm of the good ship America and takes it in a 180 degree different course, there is no other way and even then it will take half a decade to clear the tourism setting that it now has and rebuild trust (which will speculatively take 3-5 years).
So as we were given “But Trump on Tuesday pointed to another goal — regaining US access to Venezuelan oil production.” as well as “Caracas blasted Trump’s announcement on Tuesday, saying he aimed at “stealing the riches that belong to our homeland.” Venezuela has been sidestepping US oil sanctions for years, selling crude at a discounted price on the black market, mainly to China. Venezuela is estimated to have oil reserves of some 303 billion barrels, according to the Organization of the Petroleum Exporting Countries (OPEC) — more than any other nation. “If there are no oil exports, it will affect the foreign exchange market, the country’s imports … There could be an economic crisis,” Elias Ferrer of Orinoco Research, a Venezuelan advisory firm, told AFP recently.” As I personally see it (and I might be wrong) America is broke and it is about to lose whatever it has to pay for the interest on the loans they have. The Administration had a setting they tried and it backfired. Greenland isn’t giving up its land, Canada is turning down America and worse still, Canada is now making headway in impressive economic strides for Canada which is also hurting America. As I see it, the stage that was left was to ‘annex’ the Venezuelan oil fields. This is likely to fail, but more disastrous nearly all lands will gain mistrust of the American way which is now showing to be selfish at the expense of all others. That is as I see it the Legacy that President Trump is leaving behind and the sooner others see it the way (several already do) the more America sees the hurt it imposed on itself.
And when places like Del Monte is filing for bankruptcy, it will not be alone ad the more these places are hidden due to ‘National Security’ or whatever reason is given and others are seemingly ready to follow. There is American Unagi, American Signature, parent company of furnishings retailers American Signature Furniture and Value City and more are on the list of those reading Chapter 11 of the book of economic hardship. All these facts are settings that give America a stage of disaster and the American administration remains in denial.
Even if America succeeds with Venezuela, America is done for. No-one will trust America for decades. Not the EU, not the Commonwealth and parts of Asia will also shun America. And for a lot Canada is the more trustworthy option, so Canada will de decently well and as we recently saw Lockheed Martin is getting replaced by Saab AB and that is merely the tip of the iceberg. So whilst America withdraws the troops from Europe, Europe has one card left to play. It can throw America out of NATO and that has massive repercussions. You see America has 70,000 troops in Europe, those who are send back will likely lose their jobs, then they get a massive downturn in their defense industry. Which will upset Raytheon, Northrop Grumman and Lockheed Martin. All that has a massive economic footprint. When the Europeans turn away from American hardware, America’s economy takes a swift dive into an abyss where it cannot afford the gravy trains it supported and that has other impacts as well. I reckon that the media is next, as American media gets shunned in Europe and the Commonwealth their incomes and more important their influence will wane into near nothingness.
So am I correct?
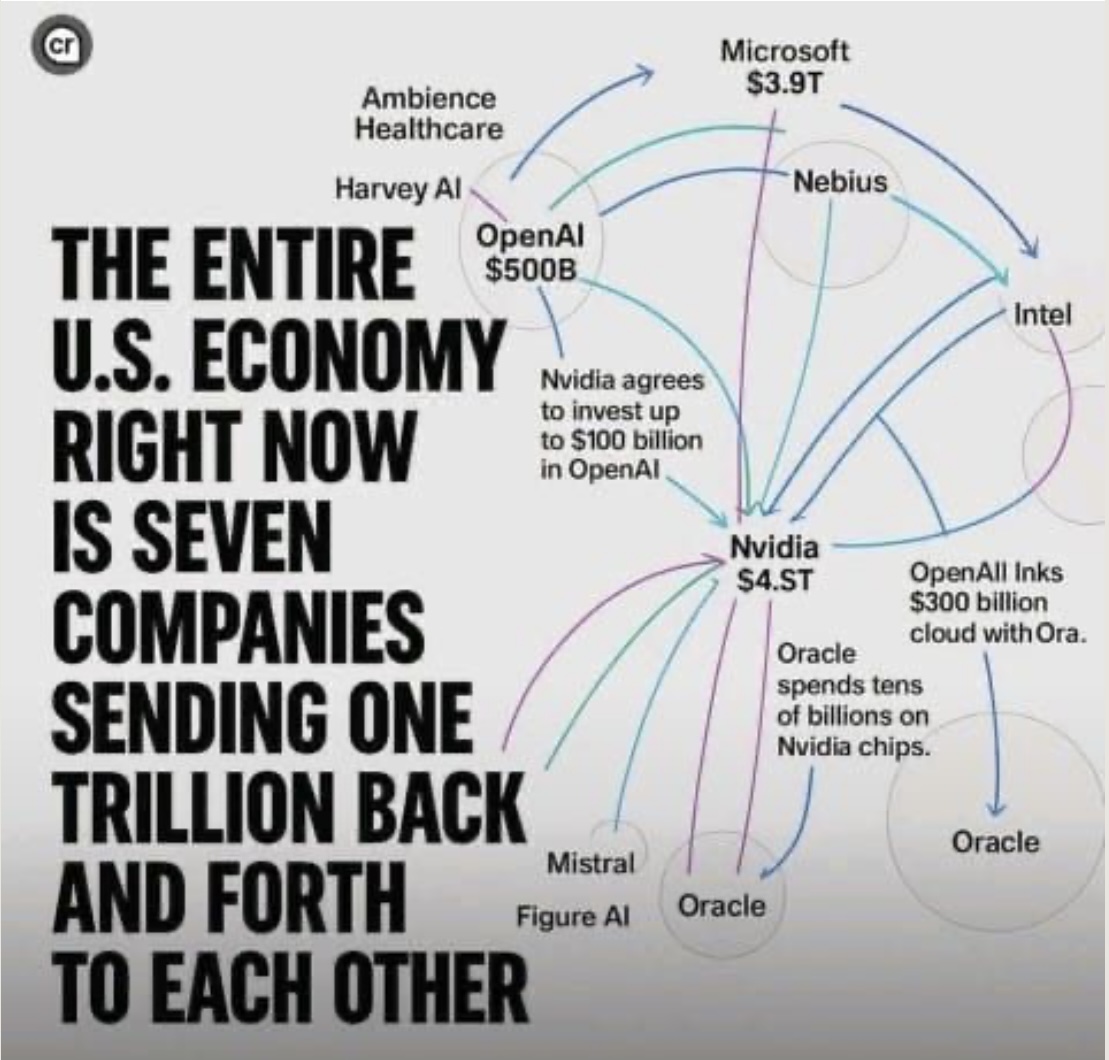
I honestly don’t know, but that is what I see, the markers are undeniable and they tend to cross nations, they cross interests and they cross political allies. As I see it, America might in the end have one ally left, Russia. So how does that sit with the anti-communist setting of the Republican Party? And next on that list id the waning of the CIA, you see as the Commonwealth stops trusting America, the CIA us also shunned from the meetings it needs to have and as such it is about to require a lot more money to stay afloat and that is the one thing America no longer has (at least until they get the Venezuelan oil) settings upon settings that sets the game that will be played and America is largely out of moves. They are about to falter in intelligence, they are faltering in business, the will soon falter in media and as I see it, the steps the American administration made towards Hollywood is strengthening Canadian, Australian and British film industries and those settings are getting larger and worse for America. So feel free to disagree and that is fine, but I reckon you need to investigate on yourself and see what the media is hiding from a lot of people. And as I see it, America is about to falter and leave the people in America without anything. Because the AI scare fare is about to cost American wealth trillions of dollars (according to some a number between nine and fifteen) who who gets to pay for all that? Microsoft? OpenAI? I reckon that it will come out of retirement funds and if I am wrong, I am wrong. But do come with actual numbers. We can see “US retirement funds are extensively invested in artificial intelligence (AI), primarily through large index funds, mutual funds, and ETFs that hold significant stakes in major tech companies leading the AI revolution, such as Nvidia, Microsoft, and Alphabet.” As well as “Indirect Investment via Large Cap Tech Holdings: Many common retirement savings options, like S&P 500 index funds or target-date funds, have a large, concentrated exposure to the “Magnificent Seven” tech stocks (Nvidia, Microsoft, Meta, etc.) that are heavily driving AI innovation. Nvidia’s significant market value, for example, means it has a large weighting in many diversified portfolios, creating inherent AI exposure.” That is the bubble fear you should have and when America stops, you better have a sock with reserve funds, because that is all you can live on when it collapses.
Have a great day.