That is the setting as I personally believe it to be. The problem isn’t me, the problem is that politicians are clueless and as such the people will end up suffering. As we get the article (at https://www.theguardian.com/technology/2025/jul/30/zuckerberg-superintelligence-meta-ai) telling us ‘Zuckerberg claims ‘super-intelligence is now in sight’ as Meta lavishes billions on AI’ the dwindling situation is overlooked. This is not on Meta or on Mark the innovator Zuckerberg, well, perhaps it is a little on him. But the setting of “Whether it’s poaching top talent away from competitors, acquiring AI startups or proclaiming that it will build data centers the size of Manhattan, Meta has been on a spending spree to boost its artificial intelligence capabilities for months now”. So, what are you missing? It is easy to miss it and unless you are savvy in data, there is absolutely no blame on you. I will blame politicians shoving the buck to a pile that has no representation and I do see that the political mind is merely ‘money savvy’, it does not have an alleged clue on data verification. There is a second point, it was given to me by someone (I don’t remember who) who gives us “All AI startups are their own shells linking to ChatGPT” I see the wisdom of that, but I never investigated that myself. You see, all these shells have issues with verification and these startups don’t have the resources to properly verify the data they have, so you end up having a bucket with badly arranged and misliked data. You would think that if they all link to ChatGPT it is a singular issue, but it is not. Language is one, interpretation of what is, is another side and these are merely two sides in a much larger issue. And hiding behind “build data centers the size of Manhattan” is nothing else than a massive folly. You see, what will power this? Most places in this world have a clear shortage of power and any data centre relying on power that isn’t there will crash with some regularity and these data links are maintained in real time, so links will go wrong again and again. And that link is seen by ‘some’ as “A new study of a dozen A.I. -detection services by researchers at the University of Maryland found that they had erroneously flagged human-written text as A.I. -generated about 6.8 percent of the time, on average” that implies that 1 in 15 statements are riddles with errors and there is no way around it until the verification passes are sorted out. Consider that one source gives us “monthly searches to more than 30.4 million during the last month”, this gives us that AI events resulted in 2,026,666 possible erroneous results and when that happens to something that was essential to your needs? When technical support and customer care fails because the number, aren’t right? How long will you remain a customer? That is the folly I am foreseeing and when all these firms (like Microsoft) are done shedding their people and they realise that the knowledge they actually had was pushed out of the side door? Where does this leave the customers? Will they remain Microsoft, Amazon, IBM or Google customers? This is about to hit nearly every niche in America business. The ones that held on the their people knowledge base tend to be decently safe, but the resources needed to clean up the mess that this created will scuttle the European and American economies as they overextended the new they spun themselves and when reality catches up, these people will see the dark light of a self created nightmare.
So in retrospect consider “Behind the hype of Microsoft backing and a $1B+ valuation, the company reportedly inflated numbers, burned through ~$450M funding, and collapsed into insolvency.” This setting was hyped on every channel and praised as a solution. It took less then a year to go from a billion to naught. How many even have a billion? Considering that Microsoft backed it, implies that they were unaware how they were, driven by a simple setting that should have been verified before they even backed it to over a $1,000,000,000 plus.
Now, we can feel sorry for Zuckerberg, not for the money, he probably has more in his wallet, but the ones wanting in on such a ‘great endeavor’ are bound to lose everything they own. This is a very slippery slope and as governments are seeing what some call as AI as a solution to solve a expensive setting in a cheap way are likely to lose the ownership of data of their entire population and these systems do not care who the owner is, they copy EVERYTHING. So where will that data end up going? I wonder who looked at the ownership of collected data and all the errors it has within itself.
The fear is not what it costs, but for billions of people is where their information will end up being and these politicians sell ‘sort of solutions’ which they cannot back with facts and in the end it will end up being the problem of a software engineer and that setting was too complicated to understand for any politician who was too eager to put his name under this and merely will shrug saying ‘I’m sorry’ whilst he is exiting through any side door with his personal wallet filled to the brink to a zero tax nation with a non-extradition treaty.
A setting we will see the media repeat time after time without seriously digging into the mess as they told us “Wall Street investors are happy with the expensive course Zuckerberg is charting. After the company reported better-than-expected financial results for yet another quarter, its stock soared by double digits.” All whilst the statement “Zuckerberg did not provide any details of what would qualify as “super-intelligence” versus standard artificial intelligence, he did say that it would pose “novel safety concerns”. “We’ll need to be rigorous about mitigating these risks and careful about what we choose to open source,”” is trivialized to the largest degree and in all this there is no setting of verification. Weird isn’t it?
So feel free to enjoy you cub of toffee and don’t worry about the jacked setting of demonstration which was tracked by the original AI as “enjoy your cup of coffee and don’t worry about the impact of verification” because that is the likely heading of the coming super-intelligence
That is at times the issue, I would add to this “especially when we consider corporations the size of Microsoft” but this is nothing directly on Microsoft (I emphasize this as I have been dead set against some ‘issues’ Microsoft dealt us to). This is different and I have two articles that (to some aspect) overlap, but they are not the same and overlap should be subjectively seen.
The first one is BBC (at https://www.bbc.com/news/articles/c4gdnz1nlgyo) where we see ‘Microsoft servers hacked by Chinese groups, says tech giant’ where the first thought that overwhelmed me was “Didn’t you get Azure support arranged through China?” But that is in the back of my mind. We are given “Chinese “threat actors” have hacked some Microsoft SharePoint servers and targeted the data of the businesses using them, the firm has said. China state-backed Linen Typhoon and Violet Typhoon as well as China-based Storm-2603 were said to have “exploited vulnerabilities” in on-premises SharePoint servers, the kind used by firms, but not in its cloud-based service.” I am wondering about the quote “not in its cloud-based service” I have questions, but I am not doubting the quote. To doubt it, one needs to have in-depth knowledge and be deeply versed in Azure and I am not one of these people. As I personally see it, if one is transgressed upon, the opportunity rises to ‘infect’ both, but that might be my wrong look on this. So as we are given ““China firmly opposes and combats all forms of cyber attacks and cyber crime,” China’s US embassy spokesman said in a statement. “At the same time, we also firmly oppose smearing others without solid evidence,” continued Liu Pengyu in the statement posted on X. Microsoft said it had “high confidence” the hackers would continue to target systems which have not installed its security updates.” This makes me think about the UN/USA attack on Saudi Arabia regarding that columnist no one cares about, giving us the ‘high confidence’ from the CIA. It sounds like the start of a smear campaign. If you have evidence, present the evidence. If not, be quiet (to some extent).
We then get someone who knows what he in talking about “Charles Carmakal, chief technology officer at Mandiant Consulting firm, a division of Google Cloud, told BBC News it was “aware of several victims in several different sectors across a number of global geographies”. Carmakal said it appeared that governments and businesses that use SharePoint on their sites were the primary target.” This is where I got to thinking, what is the problem with Sharepoint? And when we consider the quote “Microsoft said Linen Typhoon had “focused on stealing intellectual property, primarily targeting organizations related to government, defence, strategic planning, and human rights” for 13 years. It added that Violet Typhoon had been “dedicated to espionage”, primarily targeting former government and military staff, non-governmental organizations, think tanks, higher education, the media, the financial sector and the health sector in the US, Europe, and East Asia.”
It sounds ‘nice’ but it flows towards the thoughts like “related to government, defence, strategic planning, and human rights” for 13 years”, so were was the diligence to preventing issues with Sharepoint and cyber crime prevention? So consider that we are given “SharePoint hosts OneDrive for Business, which allows storage and synchronization of an individual’s personal work documents, as well as public/private file sharing of those documents.” That quote alone should have driven the need for much higher Cyberchecks. And perhaps they were done, but as I see it, it has been an unsuccessful result. It made me (perhaps incorrectly) think so many programs covering Desktops, Laptops, tablets and mobiles over different systems a lot more cyber requirements should have been in place and perhaps they are, but it is not working and as I see, it as this solution has been in place for close to 2 decades, the stage of 13 years of attempted transgression, the solution does not seem to be safe.
And the end quote “Meanwhile, Storm-2603 was “assessed with medium confidence to be a China-based threat actor””, as such, we stopped away from ‘high confidence’ making this setting a larger issue. And my largest issue is when you look to find “Linen Typhoon” you get loads of links, most of them no older than 5 days. If they have been active for 13 years. I should have found a collection of articles close to a decade old, but I never found them. Not in over a dozen of pages of links. Weird, isn’t it?
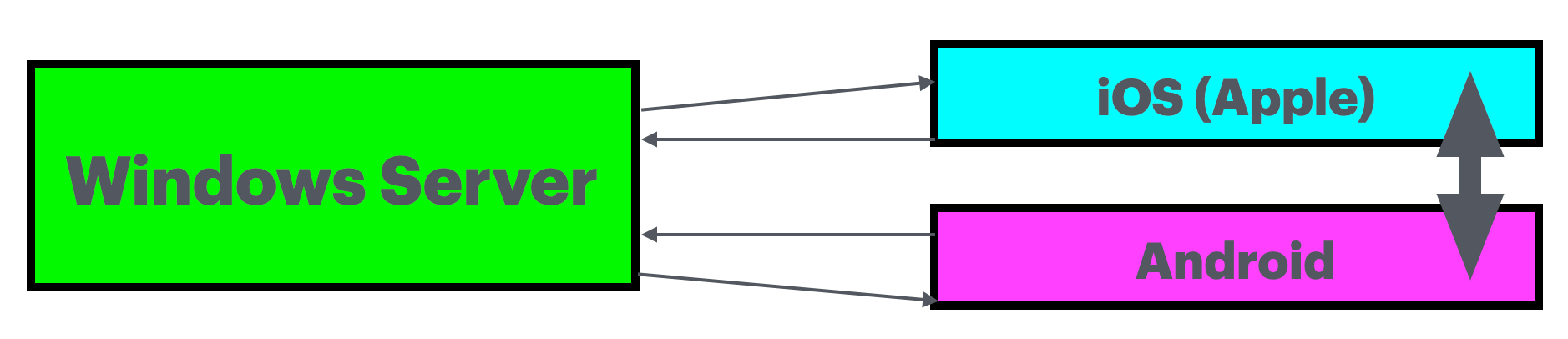
The next part is one that comes from TechCrunch (at https://techcrunch.com/2025/07/22/google-microsoft-say-chinese-hackers-are-exploiting-sharepoint-zero-day/) where we are given ‘Google, Microsoft say Chinese hackers are exploiting SharePoint zero-day’ and this is important as a zero-day, which means “The term “zero-day” originally referred to the number of days since a new piece of software was released to the public, so “zero-day software” was obtained by hacking into a developer’s computer before release. Eventually the term was applied to the vulnerabilities that allowed this hacking, and to the number of days that the vendor has had to fix them.” This implies that this issue has been in circulation for 23 years. And as this implies that there is a much larger issue as the software solution os set over iOS, Android and Windows Server. Microsoft was eager to divulge that this solution is ‘available’ to over 200 million users as of December 2020. As I see it, the danger and damage might be spread by a much larger population.
Part of the issues is that there is no clear path of the vulnerability. When you consider the image below (based on a few speculations on how the interactions go)
I get at least 5 danger points and if there a multiple servers involved, there will be more and as we are given “According to Microsoft, the three hacking groups were observed exploiting the zero-day vulnerability to break into vulnerable SharePoint servers as far back as July 7. Charles Carmakal, the chief technology officer at Google’s incident response unit Mandiant, told TechCrunch in an email that “at least one of the actors responsible” was a China-nexus hacking group, but noted that “multiple actors are now actively exploiting this vulnerability.”” I am left with questions. You see, when was this ‘zero day’ exploit introduced? If it was ‘seen’ as per July 7, when was the danger in this system solution? There is also a lack in the BBC article as to properly informing people. You cannot hit Microsoft with a limited information setting when the stakes are this high. Then there is the setting of what makes Typhoon sheets (linen) and the purple storm (Violet Typhoon) guilty as charged (charged might be the wrong word) and what makes the March 26th heavy weather guilty?
I am not saying they cannot be guilty, I am seeing a lack of evidence. I am not saying that the people connecting should ‘divulge’ all, but more details might not be the worst idea. And I am not blaming Microsoft here. I get that there is (a lot) more than meets the eye (making Microsoft a Constructicon) But the lack of information makes the setting one of misinformation and that needs to be said. The optional zero day bug is one that is riddles of missing information.
So then we get to the second article which also comes from the BBC (at https://www.bbc.com/news/articles/czdv68gejm7o) given us ‘OpenAI and UK sign deal to use AI in public services’ where we get “OpenAI, the firm behind ChatGPT, has signed a deal to use artificial intelligence (AI) to increase productivity in the UK’s public services, the government has announced. The agreement signed by the firm and the science department could give OpenAI access to government data and see its software used in education, defence, security, and the justice system.” Microsoft put billions into this and this is a connected setting. How long until the personal data of millions of people will be out in the open for all kinds of settings?
So as we are given “But digital privacy campaigners said the partnership showed “this government’s credulous approach to big tech’s increasingly dodgy sales pitch”. The agreement says the UK and OpenAI may develop an “information sharing programme” and will “develop safeguards that protect the public and uphold democratic values”.” So, data sharing? Why not get another sever setting and the software solution is also set to the government server? When you see some sales person give you that there will be ‘additional safeties installed’ know that you are getting bullshitted. Microsoft made similar promises in 2001 (code red) and even today the systems are still getting traversed on and those are merely the hackers. The NSA and other America governments get near clean access to all of it and that is a problem with American based servers and still here, there is only so much that the GDPR (General Data Protection Regulation) allows for and I reckon that there are loopholes for training data and as such I reckon that the people in the UK will have to set a name and shame setting with mandatory prosecution for anyone involved with this caper going all the way up to Prime Minister Keir Starmer. So when you see mentions like ““treasure trove of public data” the government holds “would be of enormous commercial value to OpenAI in helping to train the next incarnation of ChatGPT”” I would be mindful to hand or give access to this data and not let it out of your hands.
This link between the two is now clear. Data and transgressions have been going on since before 2001 and the two settings when data gets ‘trained’ we are likely to see more issues and when Prime Minister Keir Starmer goes “were sorry”, you better believe that the time has come to close the tap and throw Microsoft out of the windows in every governmental building in the Commonwealth. I doubt this will be done as some sales person will heel over like a little bitch and your personal data will become the data of everyone who is mentionable and they will then select the population that has value for commercial corporations and the rest? The rest will become redundant by natural selection according to value base of corporations.
I get that you think this is now becoming ‘conspiracy based’ settings and you resent them. I get that, I honestly do. But do you really trust UK Labor after they wasted 23 billion pounds on an NHS system that went awry (several years ago). I have a lot of problems showing trust in any of this. I do not blame Microsoft, but the overlap is concerning, because at some point it will involve servers and transfers of data. And it is clear there are conflicting settings and when some one learns to aggregate data and connect it to a mobile number, your value will be determined. And as these systems interconnect more and more, you will find out that you face identity threat not in amount of times, but in identity theft and value assessment in once per X amount of days and as X decreases, you pretty much can rely on the fact that your value becomes debatable and I reckon this setting is showing the larger danger, where one sees your data as a treasure trove and the other claims “deliver prosperity for all”. That and the diminished setting of “really be done transparently and ethically, with minimal data drawn from the public” is the setting that is a foundation of nightmares mainly as the setting of “minimal data drawn from the public” tends to have a larger stage. It is set to what is needed to aggregate to other sources which lacks protection of the larger and and when we consider that any actor could get these two connected (and sell on) should be considered a new kind of national security risk. America (and UK) are already facing this as these people left for the Emirates with their billions. Do you really think that this was the setting? It will get worse as America needs to hang on to any capital leaving America, do you think that this is different for the UK? Now, you need to consider what makes a person wealthy. This is not a simple question as it is not the bank balance, but it is an overlap of factors. Consider that you have 2000 people who enjoy life and 2000 who are health nuts. Who do you think is set to a higher value? The Insurance person states the health nut (insurance without claims) or the retailer the people who spend and life live. And the (so called) AI system has to filter in 3000 people. So, who gets to be disregarded from the equation? And this cannot be done until you have more data and that is the issue. And the quotation is never this simple, it will be set to thousands of elements and these firms should not have access, as such I fear for the data making it to the outer UK grounds.
A setting coming from overlaps and none of this is the fault of Microsoft but they will be connected (and optionally) blamed for all this, but as I personally see it the two elements that matter in this case are “Digital rights campaign group Foxglove called the agreement “hopelessly vague”” and “Co-executive Director Martha Dark said the “treasure trove of public data” the government holds” will be of significance danger to public data, because greed driven people tend to lose their heads over words like ‘treasure trove’ and that is where ‘errors are made’ and I reckon it will not take long before the BBC or other media station will trip up over the settings making the optional claim that ‘glitches were found in the current system’ and no one was to blame. Yet that will not be the whole truth will it?
So have a great day and consider the porky pies you are told and who is telling them to you, should you consider that it is me. Make sure that you realise that I am merely telling you what is out in the open and what you need to consider. Have a great day.
Yup, there it is. A message for Sergey Brin, big boss (aka fearless leader) of Google, aka Alphabet the leader of a firm from A to Z. And the message starts with “Wakey, wakes, its day breakey.” It is 05:53 in the morning in California now and it is Wednesday over there (I am not that early, it is 22:53 here in Sydney) even if we are on the same day, there is a difference. So I went on my merry way this morning and I forgot to charge my Google Watch 2, so I started my day with a watch on 25%. Now there is no bad ending, but it gave me an idea and this idea is meant for Sergey Brin, so he can upgrade his warez.
This is a magnet connected charge point for the Google Watch, Considering that my Google Pixel 9 Pro can share power this device could be used to charge my watch whilst having a coffee, or when sitting behind a desk. The benefit of this is that it could connect to wireless charging the phone and/or the watch using a wireless power bank, as such there are several solutions to make. There is the benefit to add it as a direct connection to a power bank, but the versatility of this as a separate device might be the better solution as this would enable the customer to choose their own power bank, or as seen as a versatile solution in other directions, even as a new third party solution.
As such this might seem like a short story (it is for Sergey), but as I was on a roll, I decided to look at something else, basically I was stuck in season 3 and I had a hard time getting progress in the series Engines, but then I remembered the game Chains of Olympus, which I never replayed on the PSP. But a thought came to me and that was connected to the Furies and in specific Orkos, but there is a link to the Hecatonchires. As such there was a new cog in the story and I was considering the approach to start in season 2 but that is basically as far as I got, but there is a new stage added to Engonos. But more on that soon, as long as I now set aside Resituam Vitam and take a new look at Engonos and transform the stories that I had put into my blog and set the papers to create the scripts for season one and two, so I reckon that I have plenty to do in the near future. But more on that later.
As such, my day is done, but there will be more options to consider tomorrow, so have a great day.
That was the setting I found myself in. There is the specific on an actual AI language, not the ones we have, but the one we need to create. You see, we might be getting close to trinary chips. You see, as I personally see it, there is no AI as the settings aren’t ready for it (I’ve told that before), but we might be getting close to it as the Dutch physicist has had a decade to set the premise of the proven Epsilon particle to a more robust setting and it has been a decade (or close to it) and that sets the larger premise that an actual AI might become a reality (were still at least a decade away), but in that setting we need to reconsider the programming language.
Binary
Trinary
NULL
NULL
TRUE
TRUE
FALSE
FALSE
BOTH
We are in a binary digital world at present and it has served our purpose, but for an actual AI it does not suffice. You can believe the wannabe’s going on about we can do this, we can do that and it will come up short. Wannabe’s who will hide behind data tables in data tables solutions and for the most (as far as I saw it) only Oracle ever got that setting to work correctly. The rest merely grazes on that premise. You see, to explain this in the simplest of ways. Any intelligence doesn’t hide behind black or white. It is a malleable setting of grey, as such both colors are required and that is where Trinary systems with both true and false activated will create the setting an AI needs. When you realise this, you see the bungles the business world needs to hide behind. They will sell these programmers (or engineers) down the drain at a moments notice (they will refer to it as corporate restructuring) and that will put thousands out of a job and the largest data providers in class action suits from start to up the wazoo.
When you see what I figured out a decade ago, the entire “AI” field is driven to nothing short of collapse.
My mind kept it in the back of my mind and it worked on the solutions it had figured out. So as I see it something like C#+ is required. An extended version of C# with LISP libraries (the IBM version) as the only one I also had was a Borland program and I don’t think it will make the grade. As I personally see it (with my lack of knowledge) is that LISP might be a better fit to connect to C#. You see, this is the next step. As I see it ‘upgrading’ C# is one setting, but LISP has the connectors required to make it work and why reinvent the wheel? And when the greedy salespeople figure out what they missed over the last decade (the larger part of it) they will come with statements that it was a work in progress and that they are still addressing certain items. Weird, I got there a decade ago and they didn’t think I was the right material. As such you can file their versions in a folder called ‘What makes the grass grow in Texas?’ (Me having a silly grin now). I still haven’t figured it all out, but with the trinary chip we will be on the verge of getting an actual AI working. Alas, the chip comes long after we bid farewell to Alan Turing as he would have been delighted to see that moment happen. The setting of gradual verification, a setting of data getting verified on the fly will be the next best thing and when the processor gives us grey scales that matter, we will see that contemplated ideas that will drive any actual AI system forward. It will not be pretty at the start. I reckon that IBM, Google and Amazon will drive this And there is a chance that they all will unite with Adobe to make new strides. You think I am kidding, but I am not. You see, I refer to greyscales on purpose. The setting of true and false is only partially true. The combination of the approach of BOTH will drive solutions and the idea of both bing replaced through channels of grey (both true and false) will be in first a hindrance and when you translate this to greyscales, the Adobe approach will start making sense. Adobe excels in this field and when we set the ‘colorful’ approach of both True and False, we get a new dimension and Adobe has worked in that setting for decades, long before the Trinary idea became a reality.
So is this a figment of my imagination? It is a fair question. As I said there is a lot of speculation through the date here and as I see it, there is a decent reason to doubt me. I will not deny this, but those deep into DML and LLM’s will see that I am speaking true, not false and that is the start of the next cycle. A setting where LISP is adjusted for trinary chips will be the larger concern. And I got to that point at least half a decade ago. So when Google and Amazon figure out what to do we get a new dance floor, a boxing square where the lights influences the shadows and that will lead to the next iteration of this solution. Consider one of two flawed visions. One is that a fourth dimension cases a 3D shadow, by illuminating the concept of these multiple 3D shadows the computer can work out 4D data constraints. The image of a dot was the shade of a line, the image of a 2D shape was the shadow of a 3D image and so on. When the AI gets that consideration (this is a flaky example, but it is the one that is in my mind) and it can see the multitude of 3D images, it can figure out the truth of the 4D datasets and it can actually fill in the blanks. Not the setting that NIP gives us now, like a chess computer that has all the games of history in its mind, so it can figure out with some precision what comes next. That concept can be defeated by making what some chess players call ‘A silly move’, now we are in the setting of more as BOTH allows for more and the stage can be illustrated by an actual AI to figure out what should be really likely to be there. Not guess work, but the different images make a setting of nonrepudiation to a larger degree, the image could only have been gotten by what should have been there in the first place. And that is a massive calculation, don’t think it won’t be deniable, the data that Nth 3D images gives us set the larger solution to a given fact. It is the result of 3 seconds of calculations, the result to a setting the brain could not work out in months.
It is the next step. At that point the computer will not take an educated guess, it will figure out what the singular solution would be. The setting that the added BOTH allows for.
A proud setting as I might actually still be alive to see this reality come to pass. I doubt I will be alive to see the actual emergence of an Artificial Intelligence, but the start on that track was made in my lifetime. And with the other (unmentioned) fact, I am feeling pretty proud today. And it isn’t even lunchtime yet. Go figure.
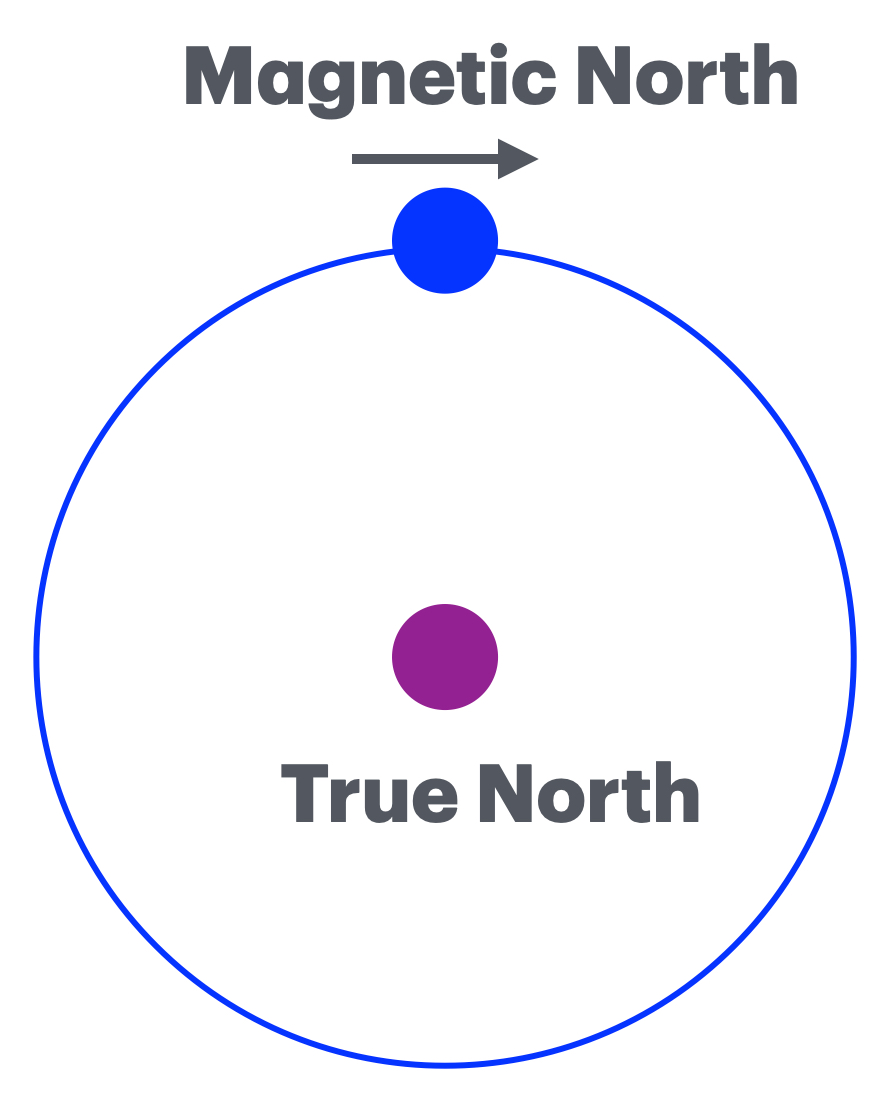
This is a setting we are about to enter. It was never rocket science, it was simplicity itself. And I mentioned it before, but now Forbes is also blowing the trumpet I mentioned in a clarion call in the past. The article (at https://www.forbes.com/councils/forbestechcouncil/2025/07/11/hallucination-insurance-why-publishers-must-re-evaluate-fact-checking/) gives us ‘Hallucination Insurance: Why Publishers Must Re-Evaluate Fact-Checking’ with “On May 20, readers of the Chicago Sun-Times discovered an unusual recommendation in their Sunday paper: a summer reading list featuring fifteen books—only five of which existed. The remaining titles were fabricated by an AI model.” We have seen these issues in the past. A Law firm stating cases that never existed is still my favourite at present. We get in continuation “Within hours, readers exposed the errors across the internet, sharply criticizing the newspaper’s credibility. This incident wasn’t merely embarrassing—it starkly highlighted the growing risks publishers face when AI-generated content isn’t rigorously verified.” We can focus on the setting about the high cost of AI errors, but as soon as the cost becomes too high, the staters of this error will get a Trump card and settle out of court, with the larger population being set in the dark on all other settings. But it goes into a nice direction “These missteps reinforce the reality that AI hallucinations and fact-checking failures are a growing, industry-wide problem. When editors fail to catch mistakes before publication, they leave readers to uncover the inaccuracies. Internal investigations ensue, editorial resources are diverted and public trust is significantly undermined.” You see, verification is key here and all of them are guilty. There is not one exception to this (as far as I can tell), there was a setting I wrote about this in 2023 in ‘Eric Winter is a god’ (at https://lawlordtobe.com/2023/07/05/eric-winter-is-a-god/) there on July 5th, I noticed a simple setting that Eric Winter (that famous guy from the Rookie) played a role in The Changeling (with the famous actor George C. Scott). The issue is two fold. The first is that Eric was less than 2 years old when the movie was made. The real person was Erick Vinther (playing a Young Man(uncredited)) This simple error is still all over Google, as I see it, only IMDB has the true story. This is a simple setting, errors happen, but in over 2 years that I reported it, no one fixed this. So consider that these errors creep into a massive bulk of data, personal data becomes inaccurate, and these errors will continue to seep into other systems. The fact that Eric Winter at some point sees his biography riddled with movies and other works where his memory fades under the guise of “Did I do this?”. And there will be more, as such verification becomes key and these errors will hamper multiple systems. And in this, I have some issues on the setting that Forbes paints. They give us “This exposes a critical editorial vulnerability: Human spot-checking alone is insufficient and not scalable for syndicated content. As the consequences of AI-driven errors become more visible, publishers should take a multi-layered approach” you see, as I see it, there is a larger setting with context checking. A near impossible setting. As people rely on granularity, the setting becomes a lot more oblique. A simple example “Standard deviation is a measure of how spread out a set of values is, relative to the average (mean) of those values.” That is merely one version, the second one is “This refers to the error in a compass reading caused by magnetic interference from the vessel’s structure, equipment, or cargo.”
Yet the version I learned in the 70’s is “Standard deviation, the offset between true north and magnetic north. This differs per year and the offset rotates in eastern direction in English it is called the compass deviation, in Dutch the Standard Deviation and that is the simple setting on how inaccuracies and confusions are entered in data settings (aka Meta Data) and that is where we go from bad to worse. And the Forbes article illuminates one side, but it also gives rise to the utter madness that this StarGate project will to some extent become. Data upon data and the lack of verification.
As I see it, all these firms relying on ‘their’ version of AI and in the bowels of their data are clusters of data lacking any verification. The setting of data explodes in many directions and that lack works for me as I have cleaned data for the better pat of two decades. As I see it dozens of data entry firms are looking at a new golden age. Their assistance will be required on several levels. And if you doubt me, consider builder.ai, backed my none other than Microsoft and they were a billion dollar firm and in no time they had the expected value of zero. And after the fact we learn that 700 engineers were at the heart of builder.ai (no fault of Microsoft) but in this I wonder how Microsoft never saw this. And that is merely the start.
We can go on on other firms and how they rely on ai for shipping and customer care and the larger setting that I speculatively predict is that people will try the stump the Amazon system. As such, what will it cost them in the end? Two days ago we were given ‘Microsoft racks up over $500 million in AI savings while slashing jobs, Bloomberg News reports’, so what will they end up saving when the data mismatches will happen? Because it will happen, it will happen to all. Because these systems are not AI, they are deeper machine learning systems optionally with LLM (Large Language Modules) parts and as AI are supposed to clear new data, they merely can work on data they have, verified data to be more precise and none of these systems are properly vetted and that will cost these companies dearly. I am speculating that the people fired on this premise might not be willing to return, making it an expensive sidestep to say the least.
So don’t get me wrong, the Forbes article is excellent and you should read it. The end gives us “Regarding this final point, several effective tools already exist to help publishers implement scalable fact-checking, including Google Fact Check Explorer, Microsoft Recall, Full Fact AI, Logically Facts and Originality.ai Automated Fact Checker, the last of which is offered by my company.” So here we see the ‘Google Fact Check Explorer’, I do not know how far this goes, but as I showed you the setting with Eric Winter has been there for years and no correction was made. Even as IMDB doesn’t have this. I stated once before that movies should be checked against the age the actors (actresses too) had at the time of the making of the movie. And flag optional issues, in the case of Eric Winter a setting of ‘first film or TV series’ might have helped. And this is merely entertainment, the least of the data settings. So what do you think will happen when Adobe or IBM (mere examples) releases new versions and there is a glitch setting these versions in the data files? How many issues will occur then? I recollect that some programs had interfaces built to work together. Would you like to see the IT manager when that goes wrong? And it will not be one IT manager, it will be thousands of them. As I personally see it, I feel confident that there are massive gaps in the assumption of data safety of these companies. So as I introduced a term in the past namely NIP (Near Intelligent Parsing) and that is the setting that these companies need to fix on. Because there is a setting that even I cannot foresee in this. I know languages, but there is a rather large setting between systems and the systems that still use legacy data, the gaps in there are (for as much as I have seen data) decently massive and that implies inaccuracies to behold.
I like the end of the Forbes article “Publishers shouldn’t blindly fear using AI to generate content; instead, they should proactively safeguard their credibility by ensuring claim verification. Hallucinations are a known challenge—but in 2025, there’s no justification for letting them reach the public.” It is a fair approach, but there is a rather large setting towards the field of knowledge where it is applied. You see, language is merely one side of that story, the setting of measurements. As I see it (using an example) “It represents the amount of work done when a force of one newton moves an object one meter in the direction of the force. One joule is also equivalent to one watt-second.” You see, cars and engineering use Joule in multiple ways, so what happens when the data shifts and values are missed? This is all engineer and corrector based and errors will get into the data. So what happens when lives are at stake? I am certain that this example goes a lot further than mere engineers. I reckon that similar settings exist in medical application, And who will oversee these verifications?
All good questions and I cannot give you an answer, because as I see it, there is no AI, merely NIP and some tools are fine with Deeper Machine Learning, but certain people seem to believe the spin they created and that is where the corpses will show up and more often than not in the most inconvenient times.
But that might merely be me. Well time for me to get a few hours of snore time. I have to assassinate someone tomorrow and I want it too look good for the script it serves. I am a stickler for precision in those cases. Have a great day.
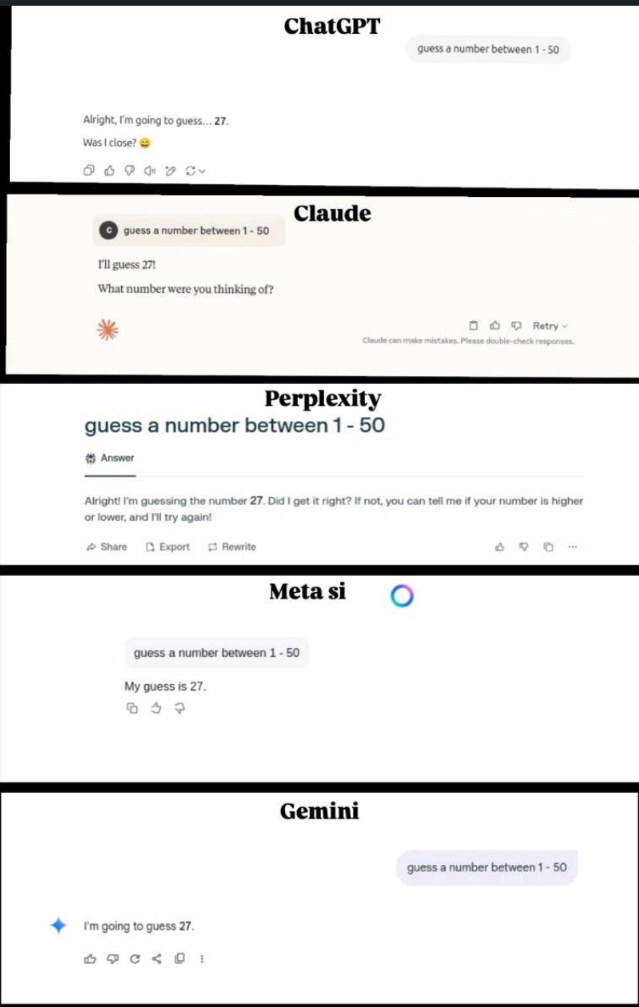
Yup that is the setting and it is a conundrum to say the least. Before I go into the explaining setting. I might need to refresh a few minds. There is no AI, Artificial doesn’t exist (yet). As I see it three components are missing and that is fine. We are making headway in this and some have one element in place. The other two are missing. So I have been speaking out against those AI ‘losers’ and it seems that no one else is listening. That’s fair. Why would you believe me over dozens of greed driven sales people. Then this morning (way too early) I saw something pass by on LinkedIn. It was brilliant, I never thought of this (I do miss parts at times) and the image below
Gives you the goods. Consider the ‘constraints’ of and actual AI. Consider the constraints of 5 AI’s. Now I take the assumption that this was all on the up and up. It is a leap, I know this. For all concerned, the poster was yanking all our chains, so you can test this yourself. Take a room with 5 strangers, ask them the simple question to pick a random number between 1 and 50 and write this on a pice of paper. Then all show them at the same time. Now if they are different people (I am referring to the old joke that all teenage boys will come up with 69 dude (and this was averted with the range 1-50) but seriously. Take 5 random people and optionally 2 might have the same answer, but for all 5 ‘proclaimed’ AI systems to give the same number is utterly impossible.
Is it? Well, that is the question. If they are founded on the same algorithm, there are optional gaps, then there is the setting that the data is founded on exactly the same amounts, as such I say impossible. A computer (any computer) has logics, hardware, algorithms and data. If they are all identical (which does not seem the case) the answers should be the same. But to get 5 identical answers is a drastic setting after all big tech is shedding jobs due to AI. If the image was true, the larger truth that companies need to shed jobs as they foresee a much larger economic clash. I was already on that page, but now more can do this to. Consider that this so called AI is being pushed onto support and customer care. Now consider that they all have the same flakes and errors. How many support and customer care jobs will set companies to collapse? It is an honest question. Where do you go when the company you are giving your money to is merely walking the beat towards average? A place where populism (aka the statistically most viable answer) is given?
A setting where we are merely the crunched number and not given the excellent quality support we are entitled to? I am not kidding, but this is the setting all the big tech companies are going for. All to look good on paper and that is what I see evolving. You can bitch all you like on Microsoft and Builder.ai where seemingly the AI work was done by 700 engineers. Microsoft backed the solution all whilst there was nothing to be seen on how 700 engineers were supported by hardware and software. Then we get to all systems with verifications and these elements should reveal that if AI was the real deal these systems could never have given all the same random number.
So, all is not over. For the simple reason that if this happens, these companies need to find 61,000 people and this gives me the setting that dataconomy.com gives with “Microsoft’s Chief Commercial Officer, Judson Althoff, stated this week that the company saved over $500 million in its call center last year through the use of AI tools. This announcement follows a series of internal remarks concerning productivity gains across sales, customer service, and software engineering, as reported by Bloomberg during a recent presentation.” When these tools start bungling their job as the data becomes an issue (I see the 5 random numbers as ‘evidence’). You see, you cannot have on and not the other. I am mentioning Microsoft in this case as the quote was there, but as I see it, IBM, Amazon and Google will all have the same issue soon enough. And the first one that realizes this will get the first grasp in the 61,000 people and the last one gets the least impressive people of the bunch. And at what point will someone figure out what the price tag is on the $500 million in savings?
It is a setting without any good end. And in the end, if the setting was faked, my conclusions are equally debatable. I will disagree as I came to this point through different means and this example was merely the icing on the cake. And I love it, because I never thought of this setting. We all miss things and I am no different. So I laugh as I saw the article as the example given was nothing short of ‘quite excellent’. As such I start the day with a smile as I enjoy being pointed at overlooking an element. That’s the person I am.
So, you all have a great day as I am starting fish day today (from young I was told Friday is fish day). Did the AI you are all embracing give you that translation and the reason why? It is a mere jab at the setting as this reenforces the verification of data. A setting I saw to be the achilles heel of that StarGate project. It is a mere $500,000,000,000 project, but that will not stop me from illustrating the situation and whilst other say that I don’t have the power to do anything. I merely counter it that these centers are unlikely to have the power to keep it going, you see power is more than an element, it becomes the biggest evil of the lot.
That was the setting I saw last night. It was after the article I wrote yesterday, and the article (at https://www.hrdive.com/news/leaders-who-laid-off-workers-due-to-ai-regretted-it/746643/) was written a few months before that. Yet it is important, because it gives me the ‘gratification’ (of sorts) that I was correct in a few way. The article called ‘More than half of leaders who laid off workers due to AI admit to screwing up’ and it comes with the byline of “Employers’ zeal for replacing humans with tech has run up against a lack of guardrails, training and clear policies around its usage” you could counter against that in a few ways and that would be OK. The part that I see as important is seen in a few ways. In the first we are given “About 4 in 10 business leaders have laid off employees as a result of deploying AI — and of those, 55% admit they made the wrong decisions about it, according to a recent survey of more than 1,000 business leaders by organizational design and planning software platform Orgvue.” It leaves me with questions. You see, on the lighter setting it sounds like a lot, but in what area where these business leaders? 55% made the wrong decision, but is it on the setting of a thousand business leaders? Or merely 150 in tourism, or 450 in tech? A top-line reference is as shallow as stating that all female pisces are prone to adultery (a GSS89, or General Social Survey joke). It is the full view we need (even if it supports my views). We are also given “Leaders also admitted to a lack of awareness on how to implement AI. One quarter said they didn’t know which roles would benefit most from AI, nearly a third didn’t know which are most at risk for automation, and 35% said lack of AI expertise was a barrier to successful deployment.” Fits the view I gave yesterday, but lacking a full view is required to give it weight. The setting of “which are most at risk for automation” requires additional awareness and the likely lack there can be shifted in nearly all directions. That being said 35% is a really large group and lacking awareness is also lacking insight into data and there verification comes into play making the lack of insight contributes to several fields and there this field merely shows more and more lack of data and awareness insight. And there the last part gets into view “leaders remain bullish on AI, the survey showed; 3 in 4 leaders said their company would be “taking full advantage” of AI by the end of the year, and 4 in 5 said they’d increase their investments this year.” So consider that in light of the lacking parts of this 3 out of 4 leader? So consider that the lack of AI and even a lack of understanding is pushing Near Intelligent Parsing (NIP) into the larger frame, as I see it without data verification and without the settings of ethical and see through constraints of data awareness. So without that, without any of that, close to 80% (4 in 5) are set to believe that there is an increase of investment? How delusional do you need to get? So whilst we see “Fearful of being left behind, employers have leaned heavily into AI over the past year.” Is this really where the FOMO people are? Is it fear of missing out, or the larger need to appease the revenue depending people? A setting where we appeal to reaching revenue against insight into how to get there, against free and gambling? Your guess is as good as mine, but in the shallow dismissal of people all over the tech field. Where we see Microsoft, Amazon, AWS, Meta and Google dismissing staff we see the emergence of a new fact. Those who are thinking this through are set in a new field. The field where hundreds of people are left outside alone, with decades of insight as the people who try to get clever with a non-existent AI will lose out to the people they fired with the decades of experience. As such the people (like Aramco and ADNOC) needing thousands of jobs and as people are getting shafted, plenty of people will look towards those regions gaining income and helping these companies getting the decades of experience pretty much overnight. That slight with the other sides will give others a larger advantage, all whilst those ‘relying’ on AI will lose more and more ground. Not the greatest of settings for these companies. So all whilst you are feasting to be dismissed, consider the door they are opening to several places and several new venues.
Do you still think I was foolish, or are facts starting to add up towards the hype some are (speculatively) falsely creating?
Have a great day and consider that Yas Island (ADNOC) is a comfortable 35-40 degrees and has 5 theme parks. I reckon not the worst setting to find a new vocation (if you have something they need) and as the west will massively learn the hard way having choices afterwards is not the worst setting either. As I said, have a great day.
Yes, this is sort of a hidden setting, but if you know the program you will be ahead of the rest (for now). Less then an hour ago I saw a picture with Larry Ellison (must be an intelligent person as we have the same first two letters in our first name). But the story is not really that, perhaps it is, but i’ll get to that later.
I will agree with the generic setting that most of the most valuable data will be seen in Oracle. It is the second part I have an issue with (even though it sounds correct), yes AI demands is skyrocketing. But as I personally see it AI does not exist. There is Generic AI, there are AI agents and there are a dozen settings under the sun advocating a non existing realm of existence. I am not going into this, as I have done that several times before. You see, what is called AI is as I see it mere NIP (Near Intelligent Parsing) and that does need a little explaining.
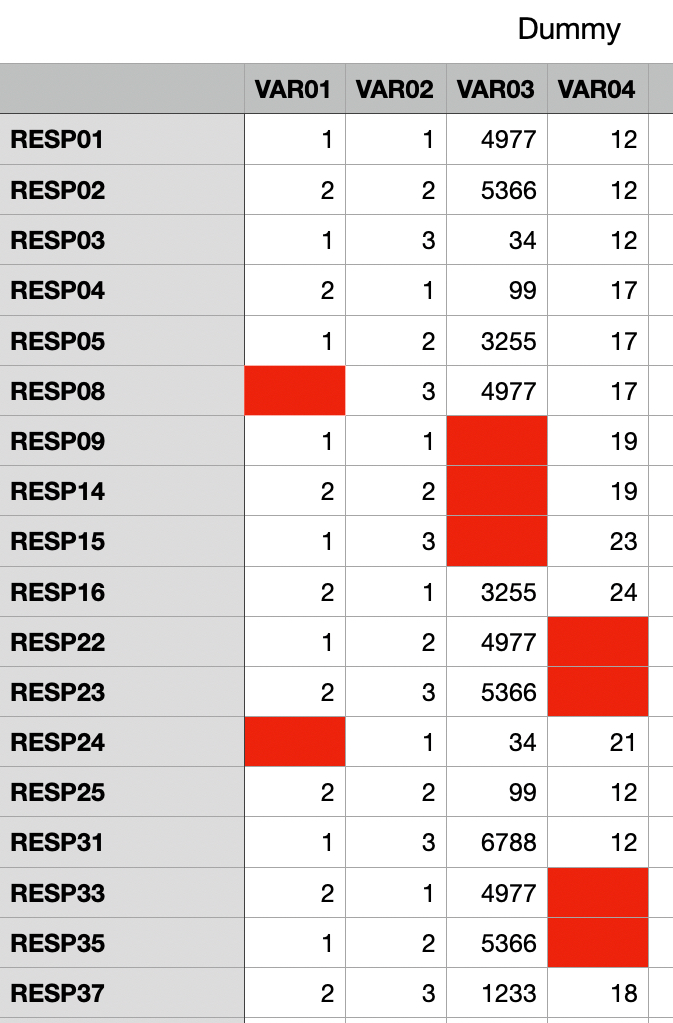
You see, like the old chess computers (90’s) they weren’t intelligent, they merely had in memory every chess game ever played above a certain level. And all these moves were in these computers. As such there was every chance that the chess computer came into a setting where that board was encountered before and as such it tried to play from that point onwards. It is a little more advanced than that, but that was the setting we faced. And would you have it, some greed driven salesperson will push the boundary towards that setting where he (or she) will claim that the data you have will result in better sales. But (a massive ‘but’ comes along) that is assuming all data is there and mostly that is never the case. So if we see the next image
You see that some cells are red, there we have no data and data that isn’t there cannot be created (sort of). In Market Research it is called System Missing data. They know what to do in those case, but the bulk of all the people trying to run and hide behind there data will be in the knowing nothing pool of people. And this data set has a few hidden issues. Response 6 and 7 are missing. So were they never there? Is there another reason? All things that these AI systems are unaware of and until they are taught what to do your data will create a mess you never saw before. Sales people (for the most) do not see it that way, because they were sold an AI system. Yet until someone teaches them what to do they aren’t anything of the sort and even after they are taught there are still gaps in their knowledge because these systems will not assume until told so. They will not even know what to do when it goes wring until someone tells them that and the salespeople using these systems will revert to ‘easy’ fixes, which are not fixes at all, they merely see the larger setting that becomes less and less accurate in record time. They will rely on predictive analytics, but that solution can only work with data that is there and when there is no data, there is merely no data to rely on. And that is the trap I foresaw in the case of [a censored software company] and the UAE and oil. There is too much unknowns and I reckon that the oil industry will have a lot more data and bigger data, but with human elements in play, we will see missing data. And the better the data is, the more accurate the results. But as I saw it, errors start creeping in and more and more inaccuracies are set to the predictive data set and that is where the problems start. It is not speculative, it is a dead certainty. This will happen. No matter how good you are, these systems are build too fast with too little training and too little error seeking. This will go wrong. Still Larry is right “Most Of The World’s Valuable Data Is in some system”
The problem is that no dataset is 100% complete, it never was and that is the miscalculations to CEO’s of tomorrow are making. And the assumption mode of the sales person selling and the sales person buying are in a dwindling setting as they are all on the AI mountain whilst there is every chance that several people will use AI as a gimmick sale and they don’t have a clue what they are buying, all whilst these people sign a ‘as is’ software solution. So when this comes to blows, the impact will be massive. We recently saw Microsoft standing behind builder.ai and it went broke. It seems that no one saw the 700 engineers programming it all (in this case I am not blaming Microsoft) but it leaves me with questions. And the setting of “Stargate is a $500 billion joint venture between OpenAI, SoftBank, Oracle, and investment firm MGX to build a massive AI infrastructure in the United States. The project, announced by Donald Trump, aims to establish the US as a leader in AI by constructing large-scale data centers and advancing AI research. Initial construction is underway in Texas, with plans for 20 data centers, each 500,000 square feet, within the next five years” leaves me with more questions. I do not doubt that OpenAI, SoftBank and Oracle all have the best intentions. But I have two questions on this. The first is how to align and verify the data, because that will be an adamant and also a essential step in this. Then we get to the larger setting that the dat needs to align within itself. Are all the phrases exact? I don’t know this is why I ask and before you say that it makes sense that they do but reality gives us ‘SQUARE-WINDOWED AIRPLANES’ 1954 when two planes broke apart in mid-flight because metal fatigue was causing small cracks to form at the edges of the windows, and the pressurized cabins exploded. Then we have the ‘MARS ORBITER’ where two sets of engineers, one working in metric and the other working in the U.S. imperial system, failed to communicate at crucial moments in constructing the $125 million spacecraft. We tend to learn when we stumble that is a given, so what happens when issues are found in the 11th hour in a 500 billion dollar setting? It is not unheard of and as I saw one particular speculative setting. How is this powered? A system on 500,000 square feet needs power and 20 of them a hell of a lot more. So how many nuclear reactors are planned? I actually have an interesting idea (keeping this to me for now). But any computer that leaks power will go down immediately and all those training time is lost. How often does that need to happen for it to go wrong? You can train and test systems individually but 20 data centers need power, even one needs power and how certain is that power grid? I actually saw nothing of that in any literature (might be that only a few have seen that), but the drastic setting from sales people tends to be, lets put in more power. But where from? Power is finite until created in advance and that is something I haven’t seen. And then the time setting ‘within the next 5 years’ As I see it, this is a disaster waiting to happen. And as this starts in Texas, we have the quote “According to Texas native, Co-Founder and CFO of Atma Energy, Jaro Nummikoski, one of the main reasons Texas struggles with chronic power outages is the way our grid was originally designed—centralized power plants feeding energy over long distances through aging infrastructure.” Now I am certain that the power-grid of a data centre will be top notch, but where does that power come from? And 500,000 sqft needs a lot of power, I honestly do not know how much One source gave me “The facilities need at least 50 Megawatts (MW) of power supply, but some installations surpass this capacity. The energy requirements of the project will increase to 15 Gigawatts (GW) because of the ten data centers currently under construction, which equals the electricity usage of a small nation.” As such the call for a nuclear reactor comes to mind, yet the call for 15 GW is insane, and no reactor at present exists to handle that. 50MW per data center implies that where there is a data centre a reactor will be needed (OK, this is an exaggeration) but where there are more than one (up to 4) a reactor will be needed. So who was aware of this? I reckon that the first centre in Texas will get a reactor as Texas has plenty of power shortages and the increase in people and systems warrant such a move. But as far as I know those things will require a little more than 5 years and depending on the provider there are different timelines. As such I have reasons to doubt the 5 year setting (even more when we consider data).
As such I wonder when the media will actually look at the settings and what will be achievable as well as being implemented and that is before we get to the training of data of these capers. As I personally (and speculatively) see it, will these data centers come with a warning light telling us SYSMIS(plenty), or a ‘too many holes in data error’ just a thought to have this Tuesday.
Have a great day and when your chest glows in the dark you might be close to one of those nuclear reactors.
That is on the table and it started 3 days when I wrote ‘The changing of games’ (at https://lawlordtobe.com/2025/06/13/the-changing-of-games/) Here I showed the setting that Microsoft opened itself to and Denmark is not the only one. There is a larger setting that America is no longer the go-to guy for European business. It is not a setting President Trump was looking for, but then he never anticipated that Microsoft would back a solution (builder.ai) with at the core a stated 700 engineers. Trust me, it matters (trusting me is always up in the air). You see, Europe and other places are now suddenly reminded how Microsoft got to the top and innovation is not the first ‘setting’ that comes to mind. Netscape and the Wordperfect corporation comes to mind in the first instance. You see, I never got to the top of anything. In part because I never heralded the limelight, in part because the people who got there feared me. I don’t back down (ever) from the setting of supporting solutions for good instead of what was politically convenient. And I am not alone., thousands of tech support and customer care people are n my side and they can now dish up the past and hit certain players where it hurts.
So now we get to TechRadar and its slightly taste adjusted setting. The story (at https://www.techradar.com/pro/denmark-wants-to-replace-windows-and-office-with-linux-and-libreoffice-as-it-seeks-to-embrace-digital-sovereignty) gives us ‘Denmark wants to replace Windows and Office with Linux and LibreOffice as it seeks to embrace digital sovereignty’ a mere 18 hours ago. It has the byline “Denmark bets big on open source revolution and control”. You see, I don’t think it is a big bet. Since the end of the 90’s when times and budgets were good, the IT setting (not merely Microsoft) was to instigate an IT armistice race and those times are gone. So whist certain players went to the ‘safety’ on IT armistice, the governments merely accepted the setting that this is how it was supposed to be, never realising they had other chances. And as I personally see it Microsoft turned that tap off towards others and redirected it to themselves. This is basically how multi-trillion companies are made. Yet the underlying setting is that there was always a larger field and Microsoft was not it. Or better stated Microsoft was not alone here, they merely tempered the setting for themselves, as this setting was never anticipated. A President that shallowed expenses and a larger premise to self. So whilst Denmark was being treated that America wants Greenland as allegedly houses a wealth of minerals, Denmark decided to look what could be done and so they did and in the process woke up Dutch politicians as well. So here we are seeing “Denmark is embarking on an ambitious effort to reduce its reliance on proprietary software from foreign tech giants by transitioning its government systems away from Microsoft offerings Windows and Office 365. The Danish Ministry of Digitalization reportedly plans a phased migration to Linux operating systems and LibreOffice for office productivity.” And as I personally see it, TechRadar is adding the ‘ambitious part’ for non-sentimental reasons. This setting was thwarted by Microsoft in the late 90’s and now they are less likely to succeed as the political field has changed. As I remember open Office is still a direction that is open. As Microsoft closes sluices they couldn’t close them all and now these sluices are the key to lose dependency to Microsoft. And here we see “The core objective, according to Minister Caroline Stage, is strategic: to safeguard Denmark’s digital infrastructure from the uncertainties of geopolitical tensions and the risk of disrupted access to US-based services.” Which is massively bad news for Microsoft because this is the one instance where they never had to protect their home guard before and here those tech support and customer care people will side with Denmark. The people Microsoft cut loose and away as it they didn’t see eye to eye to the larger need of Microsoft, those people will laugh out loud to the lacking needs of Microsoft minded people. In retrospect I saw this coming, but not in this form and not to the degree it will be hitting US-shored businesses. As such we get a few more settings, they all sound bad for Microsoft and it will enhance the needs of IBM and Oracle as they seek European sides to their business. And as we read in, we see the third player to this event. It is shown with “Denmark’s initiative is not without precedent. More than a decade ago, Germany, most notably the city of Munich, attempted to replace Microsoft products with Linux and LibreOffice.” And in that same setting, I remember that a France location had a similar idea, which is likely to have connections to Monaco and Luxembourg. As such Europe goes from 1 to 5 players and the impact on America will not be without consequences. And where TechRadar gives us, without sources “The Danish government, however, appears to be proceeding with greater caution. The rollout will be gradual, and the ministry has stated that it will temporarily revert to Microsoft tools if serious disruptions arise.” This part actually reads like a ‘divert or lose’ situation and Microsoft needs to take heed as this comes with a larger setting. You see, there is an upside for the Netherlands and out reflects back to the Wordperfect Corporation. America made Wordperfect a solution from Utah and it reflected that it was to be put down, but the Dutch had reasons for this solution. It was the first serious solution that perfectly converted syntax’s into Dutch and they had reasons to be proud as the ‘older’ reason is set to the proverbial English setting of 40,000 words and 800 exceptions to the Dutch setting of 800 words and 40,000 exceptions. You see, that was the larger conundrum and that small company in Utah figured the solutions out and that is the larger setting. Getting from Dutch to German, French and English is a breeze (as the depression goes) and after all these years. Did Microsoft protect that IP by paying for these fees year after year? I doubt it, Microsoft is at best a greedy user and it had cut off these fees after at least a decade setting them short by a decade at the very least and that is where these techies come in. They still have the bad feelings of getting cut short with the little retirement fees they were handed and they will massively support any anti-Microsoft feelings they see. So, when your birds come home to roost, they really will have a party.
I feel that TechRadar was ‘spicing’ it up with “Compatibility with Microsoft Office documents and user adaptation to a new interface may pose significant challenges.” I doubt it will be very hard. Open Office had things brewing in 2012 when they were the number one challenge and these files have not been upgraded much. The larger setting is in newer files that has solutions in place that old ones didn’t, but as far as I can tell aside from Excel files, most files can be ‘altered’ to another solution. Consider that Google Docs, Apple Pages and a few others have little to no problems to read word files. Google Sheets and Apple Numbers can for the most read Excel files and I will give Microsoft the benefit of the doubt that Excel is way advanced to those two solutions, but with the gathered intel from them and OpenOffice there are little snags to be expected. When you see that and the joke that PowerPoint has basically become that most of this setting is close to academic. There is a chance that SAP will have to ‘shed’ its neutrality by claiming it is important for its SAP Dashboard to stay with Excel as it is ‘important’ (I merely think that XCelcius was the go to solution with Excel ad that is basically what SAP Dashboard is) and they will shed that when they see the damage they will do to themselves. As I personally see it Google Sheets could step in there. So as Microsoft will be losing 50% of their solutions, the larger demise will start.
Whilst Wiki is not really a dependable source as it has no real academic value, it does serve its purpose and (at https://en.wikipedia.org/wiki/WordPerfect) we get to see “In November 2004, Novell filed an antitrust lawsuit against Microsoft for alleged anti-competitive behavior (such as tying Word to sales of Windows and withdrawal of support for APIs) that Novell claims led to loss of WordPerfect market share.That lawsuit, after several delays, was dismissed in July 2012. Novell filed an appeal from the judgment in November 2012, but the Court of Appeals for the Tenth Circuit affirmed. Novell sought review in the US Supreme Court, but in 2014 that court declined to hear the case, ending the legal action almost a decade after it had begun.” It isn’t what it states, it shows that the Novell vs Microsoft antitrust lawsuit gives Denmark the blanket it needs. I remember the massive setting the WP6 for Windows had and Microsoft used that to push its own solution (Word) and when we see this, we see that Microsoft has a government wheelbarrow (if that expression is still used) and as such Denmark has another handle to shed Microsoft (as have the other four). As I see it, in a decade the laws were meant to protect America solutions, and now we get the Canadian setting of Alludo. A Canadian firm no less and as Wordperfect is still under in France, another side opens up. And it doesn’t look good for Microsoft as the niches they created unite as one bubble against Microsoft and America. There is every chance that we will get to see new innovation but no longer in the hands of Microsoft and whilst this happens Microsoft loses market share after market share.
And as Windows support ends, the people considering shift will merely increase. As such after this I wonder if there is any case left for Azure. It makes you feel blue (and not in a good way) leaving larger gaps for players like Oracle and AWS to step in. Yes they are American, but they at least have had the good of any corporation in view of the needs of their solutions and that is where Denmark might make choices as long as these two have European clouds in mind. As fast as as I see it, they do and as Europe shift, the Arabian peninsula does to.
As this happens in my lifetime gives me a tear of joy. They say pride cometh before the fall and as I see it Microsoft will have a long way to fall down (the boom of impact might be the first boom that is globally felt and heard) as such there is a lot to be seen and soon as Satya Nadella gives ‘us’ the need for ‘friendly cooperation’ will be the first setting that is laughed away by some, but when the company is seen as ‘in danger’ it will be the first massive hit to any American operation and that will set a larger scene (what that scene is, I have no idea. As I see it, this has never happened before) and as Microsoft goes, Apple will shortly follow. It quite literally will be left without option.
So have a great day and if you are in Abu Dhabi, enjoy the Chicken Shawarma as it is lunch time there now. Have a fun day
There is the thought that games are changing and the first question becomes ‘What games?’ And that would be a correct way of thinking. Whether you decide to kill the bullies and their connections, whether you stand up for yourself or if you become a lot less visible. The latter part is my preferred way, what doesn’t see you, will not hurt you. But in the 80’s I learned the hard way that always on the defense tends to be pointless, as such I would be inclined to scurry over to the kill side. It has the benefit that the the magicians of this world get plenty scared when the bunny bites them. They aren’t used to the sight of their own blood. They tend to cry and wonder why they can’t be bullies anymore. You see, at some point people have had enough. Some like me tend to weigh the consequences of being bullied or to eradicate them and live the fallout. At some point accepting the fact to be bullied no longer weighs high enough and when the Sydney Metropolitan police departments tend to do nothing, even as they have Brodies Law at hand, they prefer not to act. It only works so far.
This story is important to the real deal, it is a story that ZDNet gives us (at https://www.zdnet.com/article/why-denmark-is-dumping-microsoft-office-and-windows-for-libreoffice-and-linux/) where we see that Denmark is now apparently ‘Why Denmark is dumping Microsoft Office and Windows for LibreOffice and Linux’ and in that setting I wonder if Danish voices might also float towards WPS Office (by Kingsoft), you see, ZDNet gives us “Denmark wants to claim “digital sovereignty.” In the States, you probably haven’t heard that phrase, but in the European Union, digital sovereignty is a big deal and getting bigger.” I see that this is one avenue I never considered. Oh, I’ve heard the term. Yet the larger setting is not what I have heard, but what is behind it. Denmark is likely furious by some bully that wants of annex Greenland (an island West of Denmark a mere 2.166 million km²) and they are decently angry and this was the first setting. After being fed up with the Trump stage, they decided to take Microsoft out of the equation. At that point a lot of settings that ‘drip’ into American data settings and in this the first stone is cast. You see, President Trump might seem to think that business will adjust towards American standards, but that is a little delusional. You see, Microsoft is seen as a 3.56 trillion company, but behind that is a towering amount of debts as well. The totality of debts is according to some A$93.09 Billion. This might not seem as much, but what ‘victories’ have Microsoft made? What spin actually represents revenue? Microsoft is all about revenue and net profit, yet the larger setting becomes “In Q3 2025, Xbox gaming revenue decreased by 7% year-on-year, but content and service sales increased by 8%.” So Microsoft sets a plus to diminish the minus, yet the larger station is that they lose a lot more than they gain, for what is the depending value of the 8% rise? It is not the same as based amount of the 7% drop. Microsoft is losing against Sony 3:1 and now that the Nintendo Switch 2 is out, these losses will merely increase overall. Whatever Microsoft has as a tablet doesn’t even dent the setting Apple has and as some see, their Azure state seemingly doesn’t hold a candle to the system some book dealer has (yes, it is AWS). Then we get the setting that their ‘edge’ yes, their browser only has a 5% market share against Google having 67%, Apple follows with 17%. Now how many failures can such a company hold? And now consider Huawei entering the field with HarmonyOS. Taking market share from both Android and iOS. That was the setting before today and now Denmark is seemingly the first to drop Microsoft for other paths in IT. So how long until Denmark convinces one of the other EU nations to follow suit? What losses will Microsoft endure before they sink some of their badly conceived projects? I don’t know, I am merely asking.
As such Microsoft is speeding to get a lot of the HarmonyOS population, but as Kingsoft grows Microsoft diminishes and the that population never had much love for Microsoft and America to begin with. And we see part of this with “EU leaders are seeking to reduce Europe’s dependence on foreign technology providers, primarily those from the United States, and to assert greater control over its digital infrastructure, data, and technological future.” And another part is that they’re concerned about who controls European data, who sets the rules, and who can potentially cut off access to essential services in times of geopolitical tension. And the tariff war doesn’t help. That setting instigated by President Trump is likely to ht Microsoft faster than they realise and what happens when these debts will rise as revenue decreases.
The next part is alleged settings and I have seen no evidence of this from other sources “President Donald Trump issued ICC sanctions. This order allegedly prompted Microsoft to lock the ICC’s Chief Prosecutor, Karim Khan, out of his email accounts, according to reports. This came after Microsoft chairman and general counsel, Brad Smith, had promised that the company would stand behind its EU customers against political pressure. Recently, however, Smith stated that Microsoft had not been “in any way [involved in] the cessation of services to the ICC,” according to Politico. When pressed, Microsoft failed to further explain how the email disconnection occurred.” That might (or not) be a complete answer. I have to add that the entire builder.ai fiasco is on the hands of Microsoft. They backed this and they never saw the 700 engineers programming what on existent AI was supposed to do. So where are these 700 systems, their OS and their Azure licenses? Wouldn’t that be firmly on the eyes of Satya Nadella? And as such, how was this worth a billion dollars? If Microsoft was entirely unaware they could be seen as incompetent (or at lease some people on the VP and higher list). If they did know there is a larger failing at Microsoft going on and as Denmark is allegedly dropping Microsoft, it is the start of a lot more bad news. But they can rely on spin to keep the eyes of others somewhere else.
And we see that (allegedly) see that in part with “Whether or not Microsoft cut services to an organization in response to Trump’s order, the fear that it could do so in the future remains. Before the Danish government announced its move, Denmark’s largest cities, Copenhagen and Aarhus, had already announced plans to phase out Microsoft software and cloud services.” So why allegedly? The setting is fear, not data and whilst we see the results we might see the wrong facts leading to this. As I personally see it “plans to phase out Microsoft software and cloud services” might be du to the fact that AWS is as I see it vastly superior (vastly might be overstating it) and fear could weasel in at any point, almost anywhere. Yet the likely accusation that Microsoft is the ‘bitch’ of President Trump or any American administration will be much harder to counter. It could set the tides against Microsoft in Denmark (for starters), Canada and McDonald islands (both users). So there is space to maneuver, yet Microsoft doesn’t do that and we are left with the accusation. And the larger setting that “In particular, the Danes are worried about Trump’s policies and that US political decisions could put public IT services at risk.” Is a decent fear to have in these days, as such Microsoft will be left holding the political bag. And Denmark is not alone here “Bart Groothuis, a Dutch member of the European Parliament, recently said, the EU “should go for a European cloud” since “Europe has a ‘problem’ with American cloud.”” I am not sure how this ‘computes’ in a downside for Microsoft, but the spin masters will have their hands full because that increases the Danish setting by 100% and there is no way telling what else is at risk and who else is to follow suit.
I saw a different variation of the ‘downfall’ of Microsoft, for the most their lack of actual innovation, their dependency on marketing spin (or whatever Microsoft calls it) and their failure to deliver in several fields. And their enemies are at the gates. After Microsoft failed the mobile markets (it is near zero) and as Huawei is gaining massive levels and Microsoft is losing market share after market share and Denmark clearly showed that they see Microsoft not as a partner but as a threat. As such I have to wonder, in what field will Microsoft fail next?