That is the setting I just ‘woke’ up from. A fair warning that this is all PURE speculation. There are no hidden traps, there is no revelation at the end. All this is speculation.
You see, some will recall the builder.ai setting and there we see “Builder.ai was a smartphone application development company which claimed to use AI to massively speed up app development. The company was based mostly in the United Kingdom and the United States, with smaller subsidiaries in Singapore and India.” At this time we are given “The real catalyst wasn’t technical failure — it was financial mismanagement. According to reports, Builder.ai was involved in a round-trip billing scheme with one of its partners. Essentially, they were allegedly booking fake revenue to make the business look healthier than it was.” And the fact that Microsoft was duped here makes it hilarious. But was it? You see, as I see it AI doesn’t exist (not yet at least) so this setting didn’t make sense, it still doesn’t. Apart from the fact that there were 700 engineers involved (which made the setting weird t say the least) and that was set in a larger space. But what if there was no ‘loss’ for Microsoft? What if builder did exactly hat was required of them? When I got that thought, another beeped up. What if this setting was a mere pilot? You see, there are data issues (all over the place) and Microsoft knows this. What if these 700 engineers were setting the larger premise. What if this is the premise that Sam Altman needs? What if the enablement the is caused between Sam Altman and Satya Nadella and their needs? What if that setting isn’t merely data, but programmers? What if OpenAI is capturing all the work created by programmers? You see, data can be collected, capturing the work of programmers is a little different and OpenAI gets at present “OpenAI is set to hit 700 million weekly active users for ChatGPT this week”, as far as I can tell 90% is simple rubbish, but that 10% are setting their fingerprints on the programming of the future. And whilst this is going on, the ChatGPT funnels are working overtime. As such these programers are pushing themselves out of a job (well not exactly) they still have jobs in several places, but the winners here is team Altman/Nadella. They are about to clean house and when the bulk of the programmers is captured, automated program settings are realised. It isn’t AI, but the people will treat it as much. And this setting is really brilliant. We all contributed to a new version of Near Intelligent Parsing. One that has the frontlines of the crowds, millions of them. And no-one is the wiser as such.
Perhaps some are and they do not care. They will have their own partitions on this all and the setting will regurgitate their logic and as such they will be the cash makers in the house. So, we are pricing ourselves out of a jobs, out of many jobs. But as I said, this is merely speculative and I have no evidence of any kind. Yet this was the setting I see coming.
Now, let see if I can dream lovely dreams involving a lovely lady, not an Grok imaginative lady of the night. You know what I mean, Twitter is filled with them at present.
Have a great day, it’s 5:00 in the morning in Vancouver, I’m almost seeing Monday morning, less than 2 hours to go.
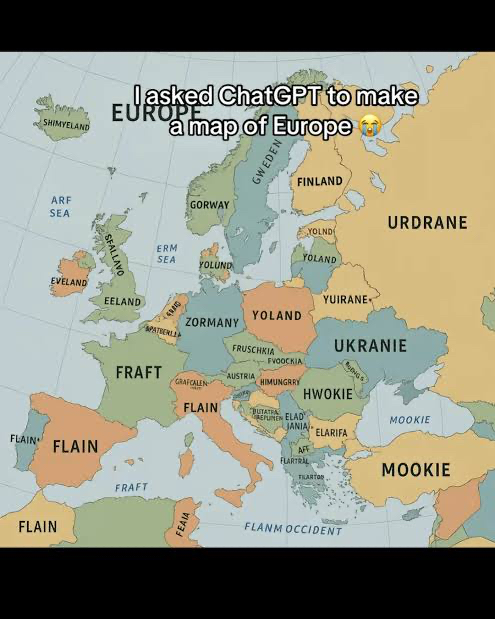
That is the setting we need to move towards and that moment will be now. It started with a simple setting, the map of Europe and the alleged accusation is seen below.
I cannot vouch for the setting, but as you see, in most languages it makes little sense. So when any AI fumbles (and that WILL happen) the ball the damage will be a lot bigger. We hear all these ‘delusional denials’ like ‘We will prepare for that’ and ‘it can’t happen to us’ you merely need to look at the Builder.ai setting and how they used 700 engineers to allegedly ‘fool’ Microsoft who backed it to the extent of a billion dollar plus. So when the ‘bigger’ players also get caught with their pants on their ankles we will have a totally new setting. As such I thought of going back to the roots of technology. Optionally as an educational setting, an optional simulator to inspire the youn to think and become creative for themselves without any AI system fumble their thinking patterns. It might not be the most eloquent setting, but creativity cannot be set in AI, as AI doesn’t exist (yet) and before it is too late, we need to create other outlets for creativity to emerge. I still like the setting that Ubisoft gave us with Assassins Creed Origins. In one of the expansions you are taken to the Tours: Beer & Bread. It shows that Egyptians ‘perfected’ the fermentation process. In my youth (a very long time ago) I went to the Open-air Museum in Arnhem (Netherlands) and this one building still reverberates in my mind over half a century later. It was a paper mill.
On the outside it doesn’t seem like much, a lot like a really old building, but that is the hidden part. Inside there is a completely operational paper mill and it is fueled by waterpower. Now you might think that this is too old.
But consider that Nobel invents Dynamite for the simple need of mining, Apparently Viagra had a completely different stage. It takes one mind to think “What if we did this?” and that is the ball game. That is the setting that creates new technologies. We need to get back to the old ways. And I use the paper mill as an example. Consider the Amish (all over America) who have been doing it there way for centuries. Consider how they have no fridges, or non electrical ones. We need to reconsider what we know and what is possible without some idiot telling us how to do it, because these people will come out of the woodworks pretending to voice the deities they pretend to follow (for their personal good).
Consider that paper mill and what to do when water stops flowing. A wind vane? Giving people the idea to take the next step. And at some point power will become an issue. We see now new ways to tarmac roads making them safer, the Netherlands are exploring illuminating forms of tarmac, making electricity less of a essential need. We see all kinds of innovations and as you think it is all covered, consider that in Australia ‘relied’ on ChatGPT (as one source stated) to phrase the law and it used non-existing cases. So how do you like your chestnuts boiled in that gravy?
The one option is to revert to earlier settings and consider what is possible without others telling us what to do. A lot will not work, but some will be true innovative steps. And that is the ballgame. As what some call AI is telling us where to go and especially where not to go we lose the creativity we have, or merely fashion it in the way other want it to be fashioned.
That is not innovation, that is pack mentality.
So what stages in other fields were short cut, because it never supported the then innovative choosers? We need to protect ourselves and the evidence is all over the historical buildings. The romans had two tiered bathhouses making hot water. So even as we now think that we do better, consider what happens when electricity falls away because 500,000 systems took it away fueling their AI systems taking over 250,000 times more energy than one simple brain does.
We need to protect what is and what was, before others remove that way of thinking from us and we can go about it in different ways, I ikon that none of them are incorrect. Another example can be seen in the old pyramids. We were given (in YouTube) “Ancient Egyptian “pyramid basalt roads” refer to a network of paved roads, including the world’s oldest known paved road, that connected basalt quarries in the Fayum region to the pyramid fields like Giza. These roads, often paved with sandstone, limestone, and even petrified wood, were used to transport massive basalt blocks, likely for paving the pyramid complexes and temples. One significant road, leading from the Widan el-Faras quarry to the shores of a now-vanished lake, represents a major engineering feat from the Old Kingdom period.” I don’t believe the hype behind it, but these roads and pavements are massive undertakings that even today are unlikely to be this perfect, apart from the settings that they seemingly lacked the tools to create these slabs and make them fit this perfectly. I am not all onboard of this, but like the Game of thrones ‘Wildfire’ we see that this reflects on what was Greek Fire and it came from Byzantine. “With the decline of the Byzantine Empire, their recipe for the production of liquid fire was lost, the last documented use of Byzantine fire was in 1187. After Constantinople fell to the Ottomans, several attempts to imitate the Greek Fire were made, but none replicated the original.” So something created 1000 years ago can no longer be reproduced? I reckon that this is one of the most direct forms of creativity lost. And the fact that it has military applications implies that plenty of governments tried to get it on their side.
As such I think we need to create genuine systems to invoke creativity in the next generation before it is all lost and we all go ‘Duh!’ At the next innovation blaming it on magic and as Vernon Dursley once said “there is no such thing as magic” as I see it, magic is blamed when we no longer comprehend the technology (like the White House and 5G technology, which comes with a small giggle from me).
So the short setting is Protect the next generation now as there is no longer any later.
That is at time the saying, it isn’t always ‘meant’ in a positive sight and it is for you to decide what it is now. The Deutsche Welle gave me yesterday an article that made me pause. It was in part what I have been saying all along. This doesn’t mean it is therefor true, but I feel that the tone of the article matches my settings. The article (at https://www.dw.com/en/german-police-expands-use-of-palantir-surveillance-software/a-73497117) giving us ‘German police expands use of Palantir surveillance software’ doesn’t seem too interesting for anyone but the local population in Germany. But that would be erroneous. You see, if this works in Germany other nations will be eager to step in. I reckon that The Dutch police might be hopping to get involved from the earliest notion. The British and a few others will see the benefit. Yet, what am I referring to?
It sounds that there is more and there is. The article’s byline gives us the goods. The quote is “Police and spy agencies are keen to combat criminality and terrorism with artificial intelligence. But critics say the CIA-funded Palantir surveillance software enables “predictive policing.”” It is the second part that gives the goods. “predictive policing” is the term used here and it supports my thoughts from the very beginning (at least 2 years ago). You see, AI doesn’t exist. What there is (DML and LLM) are tools, really good tools, but it isn’t AI. And it is the setting of ‘predictive’ that takes the cake. You see, at present AI cannot make real jumps, cannot think things through. It is ‘hindered’ by the data it has and that is why at present its track record is not that great. And there are elements all out there, there is the famous Australian case where “Australian lawyer caught using ChatGPT filed court documents referencing ‘non-existent’ cases” there is the simple setting where an actor was claimed to have been in a movie before he was born and the lists goes on. You see, AI is novel, new and players can use AI towards the blame game. With DML the blame goes to the programmer. And as I personally see “predictive policing” is the simple setting that any reference is made when it has already happened. In layman’s terms. Get a bank robber trained in grand theft auto, the AI will not see him as he has never done this. The AI goes looking in the wrong corner of the database and it will not find anything. It is likely he can only get away with this once and the AI in the meantime will accuse any GTA persona that fits the description.
So why this? The simple truth is that the Palantir solution will safe resources and that is in play. Police forces all over Europe are stretched thin and they (almost desperately) need this solution. It comes with a hidden setting that all data requires verification. DW also gives us “The hacker association Chaos Computer Club supports the constitutional complaint against Bavaria. Its spokesperson, Constanze Kurz, spoke of a “Palantir dragnet investigation” in which police were linking separately stored data for very different purposes than those originally intended.” I cannot disagree (mainly because I don’t know enough) but it seems correct. This doesn’t mean that it is wrong, but there are issues with verification and with the stage of how the data was acquired. Acquired data doesn’t mean wrong data, but it does leave the user with optional wrong connections to what the data is seeing and what the sight is based on. This requires a little explanation.
Lets take two examples In example one we have a peoples database and phone records. They can be matched so that we have links.
Here we have a customer database. It is a cumulative phonebook. All the numbers from when Herr Gothenburg got his fixed line connection with the first phone provider until today, as such we have multiple entries for every person, in addition to this is the second setting that their mobiles are also registered. As such the first person moved at some point and he either has two mobiles, or he changed mobile provider. The second person has two entries (seemingly all the same) and person moved to another address and as such he got a new fixed line and he has one mobile. It seems straight forward, but there is a snag (there always is). The snag is that entry errors are made and there is no real verification, this is implied with customer 2, the other option is that this was a woman and she got married, as such she had a name change and that is not shown here. The additional issue is that Müller (miller), is shared by around 700,000 people in Germany. So there is a likelihood that wrongly matched names are found in that database. The larger issue is that these lists are mainly ‘human’ checked and as such they will have errors. Something as simple as a phonebook will have its issues.
Then we get the second database which is a list of fixed line connections, the place where they are connected and which provider. So we get additional errors introduced for example, customer 2 is seemingly assumed to be a woman who got married and had her name changed. When was that, in addition there is a location change, something that the first database does not support as well as she changed her fixed line to another provider. So we have 5 issues in this small list and this is merely from 8 connected records. Now, DML can be programmed to see through most of this and that is fine. DML is awesome. But consider what some called AI and it is done on unverified (read: error prone) records. It becomes a mess really fast and it will lead to wrong connections and optionally innocent people will suddenly get a request to ‘correct’ what was never correctly interpreted.
As such we get a darker taint of “predictive policing” and the term that will come to all is “Guilty until proven innocent” a term we never accepted and one that comes with hidden flaws all over the field. Constanze Kurz makes a few additional setting, settings which I can understand, but also hindered with my lack of localised knowledge. In addition we are given “One of these was the attack on the Israeli consulate in Munich in September 2024. The deputy chairman of the Police Union, Alexander Poitz, explained that automated data analysis made it possible to identify certain perpetrators’ movements and provide officers with accurate conclusions about their planned actions.” It is possible and likely that this happens and there are intentional settings that will aide, optionally a lot quicker than not using Palantir. And Palantir can crunch data 24:7 that is the hidden gem in this. I personally fear that unless an accent to verification is made, the danger becomes that this solution becomes a lot less reliable. On the other hand data can be crushed whilst the police force is snoring the darkness away and they get a fresh start with results in their inbox. There is no doubt that this is the gain for the local police force and that is good (to some degree). As long as everyone accepts and realizes that “predictive policing” comes with soft spots and unverifiable problems and I merely am looking at the easiest setting. Add car rental data with errors from handwritings and you have a much larger problem. Add the risk of a stolen or forged drivers license and “predictive policing” becomes the achilles heel that the police wasn’t ready for and with that this solution will give the wrong connections, or worse not give any connection at all. Still, Palantir is likely to be a solution, if it is properly aligned with its strengths and weaknesses. As I personally see it, this is one setting where the SWOT solution applies. Strengths, Weaknesses, Opportunities, and Threats are the settings any Palantir solution needs and as I personally see it, Weakness and Threats require its own scenario in assessing. Politicians are likely to focus on Strength and Opportunity and diminish the danger that these other two elements bring. Even as DW gives us “an appeal for politicians to stop the use of the software in Germany was signed by more than 264,000 people within a week, as of July 30.” Yet if 225,000 of these signatures are ‘career criminals’ Germany is nowhere at present.
Have a great day. People in Vancouver are starting their Tuesday breakfast and I am now a mere 25 minutes from Wednesday.
That is the setting as I personally believe it to be. The problem isn’t me, the problem is that politicians are clueless and as such the people will end up suffering. As we get the article (at https://www.theguardian.com/technology/2025/jul/30/zuckerberg-superintelligence-meta-ai) telling us ‘Zuckerberg claims ‘super-intelligence is now in sight’ as Meta lavishes billions on AI’ the dwindling situation is overlooked. This is not on Meta or on Mark the innovator Zuckerberg, well, perhaps it is a little on him. But the setting of “Whether it’s poaching top talent away from competitors, acquiring AI startups or proclaiming that it will build data centers the size of Manhattan, Meta has been on a spending spree to boost its artificial intelligence capabilities for months now”. So, what are you missing? It is easy to miss it and unless you are savvy in data, there is absolutely no blame on you. I will blame politicians shoving the buck to a pile that has no representation and I do see that the political mind is merely ‘money savvy’, it does not have an alleged clue on data verification. There is a second point, it was given to me by someone (I don’t remember who) who gives us “All AI startups are their own shells linking to ChatGPT” I see the wisdom of that, but I never investigated that myself. You see, all these shells have issues with verification and these startups don’t have the resources to properly verify the data they have, so you end up having a bucket with badly arranged and misliked data. You would think that if they all link to ChatGPT it is a singular issue, but it is not. Language is one, interpretation of what is, is another side and these are merely two sides in a much larger issue. And hiding behind “build data centers the size of Manhattan” is nothing else than a massive folly. You see, what will power this? Most places in this world have a clear shortage of power and any data centre relying on power that isn’t there will crash with some regularity and these data links are maintained in real time, so links will go wrong again and again. And that link is seen by ‘some’ as “A new study of a dozen A.I. -detection services by researchers at the University of Maryland found that they had erroneously flagged human-written text as A.I. -generated about 6.8 percent of the time, on average” that implies that 1 in 15 statements are riddles with errors and there is no way around it until the verification passes are sorted out. Consider that one source gives us “monthly searches to more than 30.4 million during the last month”, this gives us that AI events resulted in 2,026,666 possible erroneous results and when that happens to something that was essential to your needs? When technical support and customer care fails because the number, aren’t right? How long will you remain a customer? That is the folly I am foreseeing and when all these firms (like Microsoft) are done shedding their people and they realise that the knowledge they actually had was pushed out of the side door? Where does this leave the customers? Will they remain Microsoft, Amazon, IBM or Google customers? This is about to hit nearly every niche in America business. The ones that held on the their people knowledge base tend to be decently safe, but the resources needed to clean up the mess that this created will scuttle the European and American economies as they overextended the new they spun themselves and when reality catches up, these people will see the dark light of a self created nightmare.
So in retrospect consider “Behind the hype of Microsoft backing and a $1B+ valuation, the company reportedly inflated numbers, burned through ~$450M funding, and collapsed into insolvency.” This setting was hyped on every channel and praised as a solution. It took less then a year to go from a billion to naught. How many even have a billion? Considering that Microsoft backed it, implies that they were unaware how they were, driven by a simple setting that should have been verified before they even backed it to over a $1,000,000,000 plus.
Now, we can feel sorry for Zuckerberg, not for the money, he probably has more in his wallet, but the ones wanting in on such a ‘great endeavor’ are bound to lose everything they own. This is a very slippery slope and as governments are seeing what some call as AI as a solution to solve a expensive setting in a cheap way are likely to lose the ownership of data of their entire population and these systems do not care who the owner is, they copy EVERYTHING. So where will that data end up going? I wonder who looked at the ownership of collected data and all the errors it has within itself.
The fear is not what it costs, but for billions of people is where their information will end up being and these politicians sell ‘sort of solutions’ which they cannot back with facts and in the end it will end up being the problem of a software engineer and that setting was too complicated to understand for any politician who was too eager to put his name under this and merely will shrug saying ‘I’m sorry’ whilst he is exiting through any side door with his personal wallet filled to the brink to a zero tax nation with a non-extradition treaty.
A setting we will see the media repeat time after time without seriously digging into the mess as they told us “Wall Street investors are happy with the expensive course Zuckerberg is charting. After the company reported better-than-expected financial results for yet another quarter, its stock soared by double digits.” All whilst the statement “Zuckerberg did not provide any details of what would qualify as “super-intelligence” versus standard artificial intelligence, he did say that it would pose “novel safety concerns”. “We’ll need to be rigorous about mitigating these risks and careful about what we choose to open source,”” is trivialized to the largest degree and in all this there is no setting of verification. Weird isn’t it?
So feel free to enjoy you cub of toffee and don’t worry about the jacked setting of demonstration which was tracked by the original AI as “enjoy your cup of coffee and don’t worry about the impact of verification” because that is the likely heading of the coming super-intelligence
That is where I saw myself. Thinking of a near forgotten great. It was 1935 and a relatively unknown director (in those days) it was his second movie for a new firm and that movie, the setting have been burned into my memory for over half a century. It takes a lot for something to happen to anyone. I am talking about the 39 steps. Even in 1935 the dangers of industrial espionage were seen as monumental and today this is worse. So as I see it. Based on the book by John Buchan, 1st Baron Tweedsmuir the movie by many that matter is seen as an absolute masterpiece (one of them is Orson Welles). As such I see a setting where someone can sort of rewrite the story to be more contemporary. The indication quote given in the movie is “The 39 Steps is an organization of spies collecting information on behalf of the foreign office of…” and we never heard the end because mr Memory was shot at that point in during the public performance. The act out of clear fear is a setting that should not be underestimated. Now, I would love to have a bite at that, but I already have three more running originals, one is a miniseries, one is a story in three seasons and one is an open endeavor spanning 3-4 seasons for now. As such my hands are full and the first work hasn’t even been sold yet. That one is a movie meant for Arabic streaming channels. As such, I need to hand it over to someone who feels frisky to go up against a great like Alfred Hitchcock. Trying to equal this masterpiece is already a herculean task, surpassing it will be close to impossible, but do try, I challenge you.
Consider the settings we have now. NIP (Near Intelligent Parsing), ‘AI’ advertisements by Facebook (or Meta) and that is merely the start. We have woke ‘idiots’ and we have religious nuts, take in measure the settings of a political administration that shoots itself in the foot, the disability of acting out against Russia and everyone is considering the yellow peril (aka China) setting the new frontier. All elements that can make a massive impact in a storyline.
So as we consider the IP that is starting to make waves (Hyper-loop, AI (aka NIP)) and that is intertwining in western, eastern and Arabic settings. If that doesn’t make for a compelling story, it is out of my hands. Oh, and before you think it is merely governments. Consider the settings that Google, Microsoft, Meta, TikTok and Huawei take on the global stage. And they all want the same thing whilst aiming for similar goals.
I think there is enough space for a rewrite of the 39 steps, the politics, business and technology are setting the stage that all want to ‘enable’ empowering that setting. And even as the 1935 original was merely implying that setting. Consider that we were given this month “Chinese theft of American IP currently costs between $225 billion and $600 billion annually.” Yet that is a two way stream. As I see it, the west has close to nothing to counter the innovations of Huawei and there is more. So what happens when a ‘dedicated’ corporation merely sets the goals towards profits and become the axial of all this? A sort of SMERSH in real life (like Bond faced in the 60’s) but there is no need for Mr. Memory. So what happens when data sets are given to OpenAI (or ChatGPT) and that system links (falsely or not) the parts that matter? So what happens to the overseers of such a system? I am merely opening doors for someone to pick up the quill and parchment (a laptop is so passé) but the idea comes across I hope. And considering last week, news with the alleged hacks by Violet Typhoon, this movie plot could thicken.
So what happens when that is the setting towards the conclusion, the middle is the start and during the movie you get start to middle in segments and that goes towards the conclusion of someone getting to the end of the story. My idea is that this could make a magnificent movie with a woman in the lead. Perhaps Florence Pugh, Jenna Ortega, Sydney Sweeney, Anya Taylor-Joy, Saoirse Ronan, or Elle Fanning could be cast. You see, this needs to be a ‘younger’ actress. As I see it under 30. A side story would be that she is into climbing, a loner that is driven to succeed in her IT/Consultancy job. Oh and these are merely characters I know off, there are plenty of actresses that could apply. I am merely thinking of the type, not the exact character and I think that this is meant for the one taking up the baton. Would be great if a Canadian or Nordic picks up that challenge. And I got a few more ideas. It could be set against actual political events of 2025. As I see it, this movie makes a massive impact if the movie starts with:
This movie is entirely fictional, any resemblance to actual persons or events is purely coincidental
As a wink to the 1932 claim against MGM is entertaining enough, but when you base this on 2025 events it will gain traction by millions of conspiracy theorists who will drive the movie along making a lot more interested in seeing this work.
A simple setting that should make Alfred Hitchcock wink at the writer and director, in equal measure Orson Welles would applaud the setting as it is a wink towards The Night That Panicked America and the October 30 1938 broadcast it was based upon. It was one hell of a peekaboo.
I reckon this can be done again and nicely on the bog screen. So if you reckon to be a script writer, here is your chance.
Have a great day. Another fine idea released before Monday morning.
That is at times the issue, I would add to this “especially when we consider corporations the size of Microsoft” but this is nothing directly on Microsoft (I emphasize this as I have been dead set against some ‘issues’ Microsoft dealt us to). This is different and I have two articles that (to some aspect) overlap, but they are not the same and overlap should be subjectively seen.
The first one is BBC (at https://www.bbc.com/news/articles/c4gdnz1nlgyo) where we see ‘Microsoft servers hacked by Chinese groups, says tech giant’ where the first thought that overwhelmed me was “Didn’t you get Azure support arranged through China?” But that is in the back of my mind. We are given “Chinese “threat actors” have hacked some Microsoft SharePoint servers and targeted the data of the businesses using them, the firm has said. China state-backed Linen Typhoon and Violet Typhoon as well as China-based Storm-2603 were said to have “exploited vulnerabilities” in on-premises SharePoint servers, the kind used by firms, but not in its cloud-based service.” I am wondering about the quote “not in its cloud-based service” I have questions, but I am not doubting the quote. To doubt it, one needs to have in-depth knowledge and be deeply versed in Azure and I am not one of these people. As I personally see it, if one is transgressed upon, the opportunity rises to ‘infect’ both, but that might be my wrong look on this. So as we are given ““China firmly opposes and combats all forms of cyber attacks and cyber crime,” China’s US embassy spokesman said in a statement. “At the same time, we also firmly oppose smearing others without solid evidence,” continued Liu Pengyu in the statement posted on X. Microsoft said it had “high confidence” the hackers would continue to target systems which have not installed its security updates.” This makes me think about the UN/USA attack on Saudi Arabia regarding that columnist no one cares about, giving us the ‘high confidence’ from the CIA. It sounds like the start of a smear campaign. If you have evidence, present the evidence. If not, be quiet (to some extent).
We then get someone who knows what he in talking about “Charles Carmakal, chief technology officer at Mandiant Consulting firm, a division of Google Cloud, told BBC News it was “aware of several victims in several different sectors across a number of global geographies”. Carmakal said it appeared that governments and businesses that use SharePoint on their sites were the primary target.” This is where I got to thinking, what is the problem with Sharepoint? And when we consider the quote “Microsoft said Linen Typhoon had “focused on stealing intellectual property, primarily targeting organizations related to government, defence, strategic planning, and human rights” for 13 years. It added that Violet Typhoon had been “dedicated to espionage”, primarily targeting former government and military staff, non-governmental organizations, think tanks, higher education, the media, the financial sector and the health sector in the US, Europe, and East Asia.”
It sounds ‘nice’ but it flows towards the thoughts like “related to government, defence, strategic planning, and human rights” for 13 years”, so were was the diligence to preventing issues with Sharepoint and cyber crime prevention? So consider that we are given “SharePoint hosts OneDrive for Business, which allows storage and synchronization of an individual’s personal work documents, as well as public/private file sharing of those documents.” That quote alone should have driven the need for much higher Cyberchecks. And perhaps they were done, but as I see it, it has been an unsuccessful result. It made me (perhaps incorrectly) think so many programs covering Desktops, Laptops, tablets and mobiles over different systems a lot more cyber requirements should have been in place and perhaps they are, but it is not working and as I see, it as this solution has been in place for close to 2 decades, the stage of 13 years of attempted transgression, the solution does not seem to be safe.
And the end quote “Meanwhile, Storm-2603 was “assessed with medium confidence to be a China-based threat actor””, as such, we stopped away from ‘high confidence’ making this setting a larger issue. And my largest issue is when you look to find “Linen Typhoon” you get loads of links, most of them no older than 5 days. If they have been active for 13 years. I should have found a collection of articles close to a decade old, but I never found them. Not in over a dozen of pages of links. Weird, isn’t it?
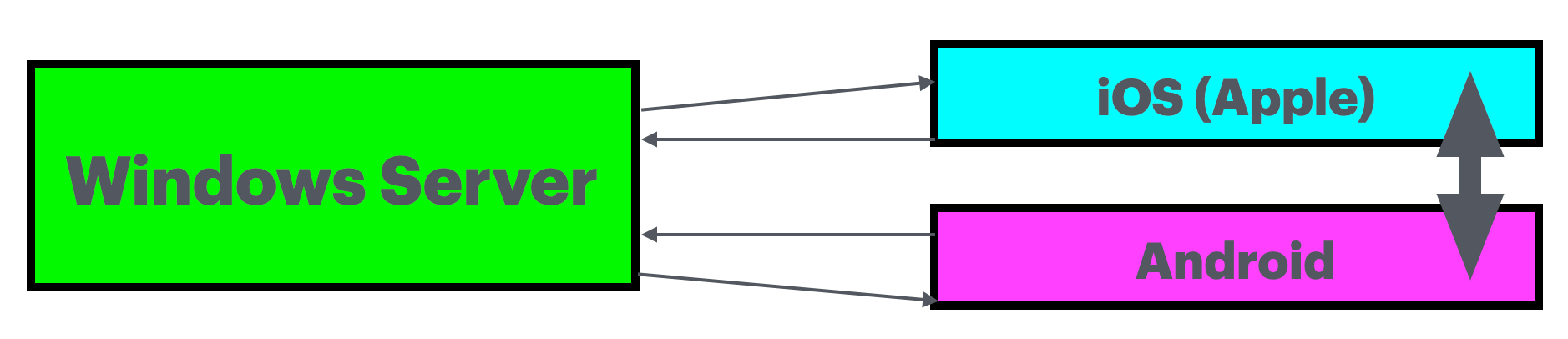
The next part is one that comes from TechCrunch (at https://techcrunch.com/2025/07/22/google-microsoft-say-chinese-hackers-are-exploiting-sharepoint-zero-day/) where we are given ‘Google, Microsoft say Chinese hackers are exploiting SharePoint zero-day’ and this is important as a zero-day, which means “The term “zero-day” originally referred to the number of days since a new piece of software was released to the public, so “zero-day software” was obtained by hacking into a developer’s computer before release. Eventually the term was applied to the vulnerabilities that allowed this hacking, and to the number of days that the vendor has had to fix them.” This implies that this issue has been in circulation for 23 years. And as this implies that there is a much larger issue as the software solution os set over iOS, Android and Windows Server. Microsoft was eager to divulge that this solution is ‘available’ to over 200 million users as of December 2020. As I see it, the danger and damage might be spread by a much larger population.
Part of the issues is that there is no clear path of the vulnerability. When you consider the image below (based on a few speculations on how the interactions go)
I get at least 5 danger points and if there a multiple servers involved, there will be more and as we are given “According to Microsoft, the three hacking groups were observed exploiting the zero-day vulnerability to break into vulnerable SharePoint servers as far back as July 7. Charles Carmakal, the chief technology officer at Google’s incident response unit Mandiant, told TechCrunch in an email that “at least one of the actors responsible” was a China-nexus hacking group, but noted that “multiple actors are now actively exploiting this vulnerability.”” I am left with questions. You see, when was this ‘zero day’ exploit introduced? If it was ‘seen’ as per July 7, when was the danger in this system solution? There is also a lack in the BBC article as to properly informing people. You cannot hit Microsoft with a limited information setting when the stakes are this high. Then there is the setting of what makes Typhoon sheets (linen) and the purple storm (Violet Typhoon) guilty as charged (charged might be the wrong word) and what makes the March 26th heavy weather guilty?
I am not saying they cannot be guilty, I am seeing a lack of evidence. I am not saying that the people connecting should ‘divulge’ all, but more details might not be the worst idea. And I am not blaming Microsoft here. I get that there is (a lot) more than meets the eye (making Microsoft a Constructicon) But the lack of information makes the setting one of misinformation and that needs to be said. The optional zero day bug is one that is riddles of missing information.
So then we get to the second article which also comes from the BBC (at https://www.bbc.com/news/articles/czdv68gejm7o) given us ‘OpenAI and UK sign deal to use AI in public services’ where we get “OpenAI, the firm behind ChatGPT, has signed a deal to use artificial intelligence (AI) to increase productivity in the UK’s public services, the government has announced. The agreement signed by the firm and the science department could give OpenAI access to government data and see its software used in education, defence, security, and the justice system.” Microsoft put billions into this and this is a connected setting. How long until the personal data of millions of people will be out in the open for all kinds of settings?
So as we are given “But digital privacy campaigners said the partnership showed “this government’s credulous approach to big tech’s increasingly dodgy sales pitch”. The agreement says the UK and OpenAI may develop an “information sharing programme” and will “develop safeguards that protect the public and uphold democratic values”.” So, data sharing? Why not get another sever setting and the software solution is also set to the government server? When you see some sales person give you that there will be ‘additional safeties installed’ know that you are getting bullshitted. Microsoft made similar promises in 2001 (code red) and even today the systems are still getting traversed on and those are merely the hackers. The NSA and other America governments get near clean access to all of it and that is a problem with American based servers and still here, there is only so much that the GDPR (General Data Protection Regulation) allows for and I reckon that there are loopholes for training data and as such I reckon that the people in the UK will have to set a name and shame setting with mandatory prosecution for anyone involved with this caper going all the way up to Prime Minister Keir Starmer. So when you see mentions like ““treasure trove of public data” the government holds “would be of enormous commercial value to OpenAI in helping to train the next incarnation of ChatGPT”” I would be mindful to hand or give access to this data and not let it out of your hands.
This link between the two is now clear. Data and transgressions have been going on since before 2001 and the two settings when data gets ‘trained’ we are likely to see more issues and when Prime Minister Keir Starmer goes “were sorry”, you better believe that the time has come to close the tap and throw Microsoft out of the windows in every governmental building in the Commonwealth. I doubt this will be done as some sales person will heel over like a little bitch and your personal data will become the data of everyone who is mentionable and they will then select the population that has value for commercial corporations and the rest? The rest will become redundant by natural selection according to value base of corporations.
I get that you think this is now becoming ‘conspiracy based’ settings and you resent them. I get that, I honestly do. But do you really trust UK Labor after they wasted 23 billion pounds on an NHS system that went awry (several years ago). I have a lot of problems showing trust in any of this. I do not blame Microsoft, but the overlap is concerning, because at some point it will involve servers and transfers of data. And it is clear there are conflicting settings and when some one learns to aggregate data and connect it to a mobile number, your value will be determined. And as these systems interconnect more and more, you will find out that you face identity threat not in amount of times, but in identity theft and value assessment in once per X amount of days and as X decreases, you pretty much can rely on the fact that your value becomes debatable and I reckon this setting is showing the larger danger, where one sees your data as a treasure trove and the other claims “deliver prosperity for all”. That and the diminished setting of “really be done transparently and ethically, with minimal data drawn from the public” is the setting that is a foundation of nightmares mainly as the setting of “minimal data drawn from the public” tends to have a larger stage. It is set to what is needed to aggregate to other sources which lacks protection of the larger and and when we consider that any actor could get these two connected (and sell on) should be considered a new kind of national security risk. America (and UK) are already facing this as these people left for the Emirates with their billions. Do you really think that this was the setting? It will get worse as America needs to hang on to any capital leaving America, do you think that this is different for the UK? Now, you need to consider what makes a person wealthy. This is not a simple question as it is not the bank balance, but it is an overlap of factors. Consider that you have 2000 people who enjoy life and 2000 who are health nuts. Who do you think is set to a higher value? The Insurance person states the health nut (insurance without claims) or the retailer the people who spend and life live. And the (so called) AI system has to filter in 3000 people. So, who gets to be disregarded from the equation? And this cannot be done until you have more data and that is the issue. And the quotation is never this simple, it will be set to thousands of elements and these firms should not have access, as such I fear for the data making it to the outer UK grounds.
A setting coming from overlaps and none of this is the fault of Microsoft but they will be connected (and optionally) blamed for all this, but as I personally see it the two elements that matter in this case are “Digital rights campaign group Foxglove called the agreement “hopelessly vague”” and “Co-executive Director Martha Dark said the “treasure trove of public data” the government holds” will be of significance danger to public data, because greed driven people tend to lose their heads over words like ‘treasure trove’ and that is where ‘errors are made’ and I reckon it will not take long before the BBC or other media station will trip up over the settings making the optional claim that ‘glitches were found in the current system’ and no one was to blame. Yet that will not be the whole truth will it?
So have a great day and consider the porky pies you are told and who is telling them to you, should you consider that it is me. Make sure that you realise that I am merely telling you what is out in the open and what you need to consider. Have a great day.
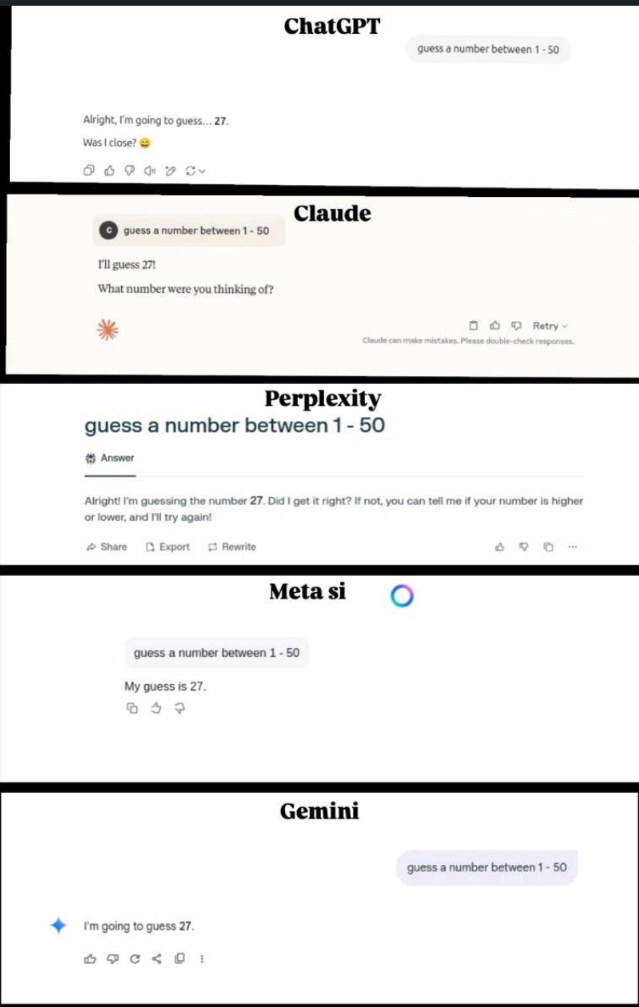
Yup that is the setting and it is a conundrum to say the least. Before I go into the explaining setting. I might need to refresh a few minds. There is no AI, Artificial doesn’t exist (yet). As I see it three components are missing and that is fine. We are making headway in this and some have one element in place. The other two are missing. So I have been speaking out against those AI ‘losers’ and it seems that no one else is listening. That’s fair. Why would you believe me over dozens of greed driven sales people. Then this morning (way too early) I saw something pass by on LinkedIn. It was brilliant, I never thought of this (I do miss parts at times) and the image below
Gives you the goods. Consider the ‘constraints’ of and actual AI. Consider the constraints of 5 AI’s. Now I take the assumption that this was all on the up and up. It is a leap, I know this. For all concerned, the poster was yanking all our chains, so you can test this yourself. Take a room with 5 strangers, ask them the simple question to pick a random number between 1 and 50 and write this on a pice of paper. Then all show them at the same time. Now if they are different people (I am referring to the old joke that all teenage boys will come up with 69 dude (and this was averted with the range 1-50) but seriously. Take 5 random people and optionally 2 might have the same answer, but for all 5 ‘proclaimed’ AI systems to give the same number is utterly impossible.
Is it? Well, that is the question. If they are founded on the same algorithm, there are optional gaps, then there is the setting that the data is founded on exactly the same amounts, as such I say impossible. A computer (any computer) has logics, hardware, algorithms and data. If they are all identical (which does not seem the case) the answers should be the same. But to get 5 identical answers is a drastic setting after all big tech is shedding jobs due to AI. If the image was true, the larger truth that companies need to shed jobs as they foresee a much larger economic clash. I was already on that page, but now more can do this to. Consider that this so called AI is being pushed onto support and customer care. Now consider that they all have the same flakes and errors. How many support and customer care jobs will set companies to collapse? It is an honest question. Where do you go when the company you are giving your money to is merely walking the beat towards average? A place where populism (aka the statistically most viable answer) is given?
A setting where we are merely the crunched number and not given the excellent quality support we are entitled to? I am not kidding, but this is the setting all the big tech companies are going for. All to look good on paper and that is what I see evolving. You can bitch all you like on Microsoft and Builder.ai where seemingly the AI work was done by 700 engineers. Microsoft backed the solution all whilst there was nothing to be seen on how 700 engineers were supported by hardware and software. Then we get to all systems with verifications and these elements should reveal that if AI was the real deal these systems could never have given all the same random number.
So, all is not over. For the simple reason that if this happens, these companies need to find 61,000 people and this gives me the setting that dataconomy.com gives with “Microsoft’s Chief Commercial Officer, Judson Althoff, stated this week that the company saved over $500 million in its call center last year through the use of AI tools. This announcement follows a series of internal remarks concerning productivity gains across sales, customer service, and software engineering, as reported by Bloomberg during a recent presentation.” When these tools start bungling their job as the data becomes an issue (I see the 5 random numbers as ‘evidence’). You see, you cannot have on and not the other. I am mentioning Microsoft in this case as the quote was there, but as I see it, IBM, Amazon and Google will all have the same issue soon enough. And the first one that realizes this will get the first grasp in the 61,000 people and the last one gets the least impressive people of the bunch. And at what point will someone figure out what the price tag is on the $500 million in savings?
It is a setting without any good end. And in the end, if the setting was faked, my conclusions are equally debatable. I will disagree as I came to this point through different means and this example was merely the icing on the cake. And I love it, because I never thought of this setting. We all miss things and I am no different. So I laugh as I saw the article as the example given was nothing short of ‘quite excellent’. As such I start the day with a smile as I enjoy being pointed at overlooking an element. That’s the person I am.
So, you all have a great day as I am starting fish day today (from young I was told Friday is fish day). Did the AI you are all embracing give you that translation and the reason why? It is a mere jab at the setting as this reenforces the verification of data. A setting I saw to be the achilles heel of that StarGate project. It is a mere $500,000,000,000 project, but that will not stop me from illustrating the situation and whilst other say that I don’t have the power to do anything. I merely counter it that these centers are unlikely to have the power to keep it going, you see power is more than an element, it becomes the biggest evil of the lot.
That is at present the larger setting, everyone wants investors and they all tend to promise the calf with golden horns. As I see it, investing in gold mining, Oil mining and a few others are near dead certain return on investments. The larger group that will seemingly want to invest in AI, the new hype word. Still, considering that Builder.ai went from a billion plus to zilch is a nice example what Microsoft backed solutions tend to give. You see, the larger picture that everyone is ignoring is that it was baked by Microsoft. Now, this might be OK, because Microsoft is a tech company. But consider that Builder.ai (previous known as Engineer.ai) was supposed to be all ‘good’, yet the media now reports ‘Builder.ai Collapsed After Finding Sales ‘Inflated By 300 Percent’’ This leads me to believe that there was larger problem with this DML/LLM solution. Another source gives us ‘Builder.ai’s Collapse Exposes Deceptive AI Claims, Shocking Major Investors’ and another source gives us ‘Builder.ai collapse exposes dangers of ‘FOMO investing’ in AI’ yet that is nothing compared to what I said on November 16th 2024 in ‘Is it a public service’ (at https://lawlordtobe.com/2024/11/16/is-it-a-public-service/) where I stated ““a US strategy to prevent a Chinese military tech grab in the Gulf region” and it is my insight that this is a clicking clock. One tick, one tock leading to one mishap and Microsoft pretty much gives the store to China. And with that Aramco laughingly watches from the sidelines. There is no if in question. This becomes a mere shifting timeline and with every day that timeline becomes a lot more worrying.” With the added “But several sources state “There are several reasons why General AI is not yet a reality. However, there are various theories as to what why: The required processing power doesn’t exist yet. As soon as we have more powerful machines (or quantum computing), our current algorithms will help us create a General AI” or to some extent. Marketing the spin of AI does not make it so.” You see, the entire DML/LLM is not AI, as we can see from the builder.ai setting (a little presumptuous) of me, but the setting that we get inflated sales and then the Register ended their article with “The fact that it wasn’t able to convince enough customers to pay it enough money to stay solvent should give pause to those who see generative AI as a replacement for junior developers. As the experience of the unfortunate Microsoft staffers having to deal with the GitHub Copilot Agent shows, the technology still has some way to go. One day it might surpass a mediocre intern able to work a search engine, but that day is not today.” Is perhaps merely part of the problem the “the technology still has some way to go” is astute and to the point, but it is not the larger problem. It reminded me of the old market research setting, take a bucket of data and let MANOVA sort it out. The idea that a layman can sort it out is hilarious. I have met over the last half a century less than a dozen people who know that they were doing. These people are extremely rare. So whenever I hear a student tell me that they had a good solution with MANOVA, my eyes were tearing with howls of deriving laughter. And now we see a similar setting. But the larger setting is not merely the coded setting of DML and LLM. It is the stage where data is either not verified or verified in the most shallow of situations. And now consider that stage with a 500 billion solution. Data is everything there and verification is one part of that key, a key too many are seeing aside because it is not sexy enough.
And now we get to the investors who are in “Fear Of Missing Out”, for them I have a consolation price. You see, RigZone gave me (at https://www.rigzone.com/news/adnoc_suppliers_pledge_817mm_investment_for_uae_manufacturing-27-may-2025-180646-article/) hours ago ‘ADNOC Suppliers Pledge $817MM Investment for UAE Manufacturing’, and as I see it Oil is a near certainty of achieving ROI, and as everyone is chasing the AI dream (which of course does not exist yet) those greedy hungry money people are looking away from the certainty piggybank (as I personally see it) and that kind of investment for manufacturing will bring products, sellable products and in the petrochemical industry that is like butter with the fish. A near certainty on investment. I prefer the expression ‘near certainty’ as there is always some risk, yet as I see it, ARAMCO and ADNOC are setting the bar of achievement high enough to get that done and as I see it “ADNOC said the facilities are situated throughout the Industrial City of Abu Dhabi (ICAD), Khalifa Economic Zones Abu Dhabi (KEZAD), Dubai Industrial Park, Jebel Ali Free Zone (JAFZA), Sharjah Airport International Free Zone (SAIF Zone), and Umm Al Quwain. They will generate over 3,500 high-skilled jobs in the private sector and produce a diverse array of industrial goods such as pressure vessels, pipe coatings, and fasteners.” As such the only danger is that ADNOC will not be able to fill the positions and that is at present the easiest score to settle.
So as we see the call for investors coming from the sound of a dozen bugles, remember that the old premise that getting the call from a setting that works beats the golden horns that some promise and the investors will need another setting (or so I figure). And in the end, the larger question is why builder.ai was backed inn the first place. Microsoft has a setting with OpenAI and as one source gives me “Microsoft and OpenAI have a significant partnership, where Microsoft is a major investor and supports OpenAI’s advancements, and OpenAI provides access to powerful language models through Microsoft’s Azure platform. This partnership enables Azure OpenAI Service, which provides access to OpenAI’s models for businesses, and it also includes a revenue-sharing agreement.” I cannot vouch for the source, but the idea is when this is going on, why go to it with builder.ai? And was builder.ai vetted? The entire setting is raising more questions than I normally would have (sellers have their own agenda and including Microsoft in this is ‘to them’ a normal setting) I do not oppose that, but when we see this interaction, I wonder how dangerous that Stargate will be and $500,000,000,000 ain’t hay.
And going back to ADNOC we see “ADNOC’s commercial agreements under the In-Country Value (ICV) program have enabled facilities that allow businesses to benefit from diverse commercial opportunities, the company said. The ICV program aims to manufacture AED90 billion ($24.5 billion) worth of products locally in its procurement pipeline by 2030.” More impressive is the quote “ADNOC’s ICV program has contributed AED242 billion ($65.8 million) to the UAE economy and created 17,000 jobs for UAE nationals since 2018, according to the company.” You see, such a move makes sense as the UAE produces 3.22 million barrels per day, that has been achieved from 2024 onward and some say that they exceeded their quota (by how much is unknown to me). But that makes sense as an investment, the entire fictive AI setting does not and ever since the builder.ai setting it makes a lot less sense, if not for the simple reason that no one can clearly state where that billion plus went, oh and how many investments collapsed and who were those investors. Simple questions really.
Have a great day and try not to chase too many Edsel’s with your investment portfolio.
The news hit me somewhere yesterday. I got it by means of a LinkedIn mention, and it gave me reason to pause. Here is one version of that news (at https://techwireasia.com/2025/04/microsoft-pauses-key-builds-in-indonesia-us-and-uk-amid-infrastructure-review/) with the mention ‘Microsoft pauses data centre investment in Indonesia, US, and UK’, and here we see the byline “Microsoft pauses or delays data centre projects in the UK, US, and Indonesia.”, it is my view that they cannot afford this setting. You might have heard the American expression, “Go big or go home” and I think that Microsoft is about to go home. You see, I have forever had the clear opinion that there is no AI. I call it NIP (Near Intelligent Parsing), the setting that if too many start accepting the setting that I was always right (which comes from the clear setting that there is one AI station and it was given to us by Alan Turing) the people will realise that there is no AI and it comes down to programming and a programmer. That setting puts Microsoft in hot water for a lot of heavy water (to be poured over their heads). And lets be clear, a side you can confirm with mere logical thinking. A data Centre is a long term setting. No matter what you put in the White House (by some called the village idiot) whatever this administration is, it is short term and a data centre is long term and that so called hype around their AI should never waver. You see, this short term action (read: knee jerk reaction) implies short term planning and that is where they all get into hot waters. Why did you think that I made mention that Google needs to put a data centre in Iceland and consolidate their thinking into geo thermal reactors? (Reactors might not be the right word). A setting where ceramic tiles (or cylinders) surrounding new constructions that is not unlike a nuclear reactor, but the reactor is all around them, not Uranium rods, the Lava (or Magma) is the powerful and as it is merely bleeding the radiation, the fuel never dissipates and never ending energy is theirs. For all these parties looking of creating data centers (as far as I can see around 50 in total globally) they will all require energy and as one data centre takes energy close to a amount a small city does, we will get energy issues a lot sooner than we think.
Did Microsoft think this through? Pretty sure they did and their conclusion is that they cannot spend billion on data centers. So at the same time as we are given “Rivals Oracle and OpenAI ramp up investments”, I come to the conclusion that Microsoft can no longer afford the bills their ego’s committed themselves to. Feel free to disagree, but they set out this AI ‘vibe’ and own 49% of OpenAI, so why close down their Data Centers whilst they ‘own’ one of the ramp up partners? They are figuring out that they are too deeply committed. And as the world realizes that NIP is not the same as actual AI, they fear what is coming next.
So you decide what to make of the stage of “Microsoft has acknowledged changing its strategy but declined to provide details about specific projects. “We plan our data centre capacity needs years in advance to ensure we have sufficient infrastructure in the right places,” a Microsoft spokesperson said. “As AI demand continues to grow, and our data centre presence continues to expand, the changes we have made demonstrates the flexibility of our strategy.”” As I see it, it is an answer, but not the one that touches on this. I come with questions as ‘What growth?’ All this sets the need for some lowered activity, not pausing, unless you know what comes next and there is a larger setting with Oracle, Tencent and Huawei, I know there is a Swedish centre as well but I forgot the name. All these are ramping up, but Microsoft is pausing? That makes no sense unless there is another reason and my thought of “They can no longer afford it” takes another gander and when we consider that they paused “North Dakota, Illinois, Wisconsin, the UK midlands and Jakarta, Indonesia.” That implies something is going on and when we combine this with “Microsoft cuts data centre plans and hikes prices in push to make users carry AI costs” (source: The Conversation, March 3rd 2025) these elements together implies (imply, not proven) tells me that there is a funding setting for Microsoft. Combine that with the lovely voiced fact of “OpenAI brought in US$3.7 billion in revenue – but spent almost US$9 billion, for a net loss of around US$5 billion.” (Source: the Conversation) we see another failed setting and that failure gets to be bigger. As Amazon, Google, Oracle, Tencent and Huawei steam ahead getting larger data centers and ready long before Microsoft is there means less revenue for Microsoft. I did say that they could go big or go home? I reckon that Microsoft already lost 6 times on front settings and they lost to Amazon, Apple (twice), Sony, Adobe, Google, and IBM. I should add Huawei to that list but they already bungled that setting before Huawei became an actual competitor. A simple deduction from little stupid old me.
So whatever you do, you might look into the trust you gave Microsoft and see that you are not left with an empty shell. Oh, and to prove that I am not anti-Microsoft you need to know that they did corner the spreadsheet market (Excel) and the flight Simulator market. Microsoft did some things good, but when it comes to the spin setting of vibes they need to reassess their situation.
Have a great day, it’s midweek now. I am happily in the next day.
There is an uneasy setting. I get that. You see AI does not exist, and whilst we all see the AI settings develop and some will be setting (read: gambling) 500 billion dollars on that topic, we now see that META is banking on a 200 billion on the stage. But what is this stage? We can tun to Reuters who gives us ‘Meta in talks for $200 billion AI data center project, The Information reports’ (at https://www.reuters.com/technology/meta-talks-200-billion-ai-data-center-project-information-reports-2025-02-26/) where we are given “A Meta spokesperson denied the report, saying its data center plans and capital expenditures have already been disclosed and that anything beyond that is “pure speculation”” However, when we set the stage on a different shoe we see another development. You see, when we think of this in non-AI terms we get that a Data Centre generally ranges from $10 million to $200 million with a typical commercial data center costing around $10-12 million per megawatt of power capacity; smaller data centers can cost as low as $200,000 to build. So when we consider that the upper range of a data centre is $200 million. So what kind of a data centre gives the need to be a thousand times bigger? Now, consider that there are enough people clarifying that AI does not exit. I see AI what some people call True AI and that springs from the mind of Alan Turing. He set the premise of AI half a century ago. And whilst some of the essential hardware is ready, there are still parts missing. Yet what some now call AI is merely Deeper Machine Learning and it gets help from an LLM. This setting requires huge amounts of data, so when you consider that that data comes from a data centre. What on earth is META up to? When need a data centre a thousand times bigger? The only size that makes sense for 200 billion is a data centre that could gobble up whatever Microsoft has as well as Google’s data centers in one great swoop and that is merely the beginning.
Speculation The next part is speculation, I openly admit that. So when (not if) America defaults on their loans we get an implosion of current wealth and the new wealth will be data. Data will in the near future be the currency that all other parties accept. As such Is META preparing for a new currency? As I see it the simplest setting is whomever has the most data will be the richest person on the planet and that would make sense, that explains Trump’s 500 billion for a data centre and now META is following suit. You see Zuckerberg is really intelligent. I saw that setting 5 years before Facebook existed, but my boss told me that my idea was ludicrous, it would never work. Now we see my initial idea spread all over the planet with every marketing organisation on the planet chomping at the bit to get their slice of pie. So Zuckerberg does have the cajones and the drive to proceed. When data is currency they will be one of the few players in the new economy. And when you take my speculation (possibly even insightful presumption) these data centers make sense and being able to set predictive data learned from active and historical data makes sense in a very real way. Predictive data will be the wave of the future. It still is not AI, but it is in very real ways the next step in data needs. Predictive analytics set the path of this wave 1-2 decades ago. And now we see more data transformations and when the main roads are dealt with the niche markets can be predicted and seen in very real ways.
And the stage is more real than you can see. When people like Zuckerberg are cashing out to get their data centers up and running, there is a real drive to be first to cash in. As I see it, my next step would be to score a job with a data centre doing mere maintenance and support work. You see, as all these big players evolve their needs, their manpower will need to come from infrastructures that these data centers require. So support and power will have the greatest staffing needs in the next decade. Just my thoughts on the matter.