That has been on my mind for a while. You see, Nintendo has Mario Kart and no one has anything to offer against that. Now, that is nothing to be ashamed of. Mario Kart has its own following, I like Mario Kart. But it is a shame that Sony never had its equal on that. A racing game with a little fun. On the SEGA Dreamcast there was Wacky Races and as I was watching some pages, I saw that this original cartoon still has its own following. Even now, after 54 years there are plenty of people that like this cartoon and what is there not to like?
So even as I loved the gamed on the dreamcast, I am proposing that Sony (preferably) makes a few alteration. Not on the graphics or the cars, that is fine, but the setting of the tracks. Especially as the PS5/PS6 have a lot more power than the Dreamcast had 16 MB RAM, 8 MB video RAM, and 2 MB audio RAM, running on a Hitachi SH-4 @ 200 MHz, which had 480 MIPS. The PS5 has 16 GB GDDR6 SDRAM running on a 8-core AMD Zen 2, which has a multitude of the ability of the
Hitachi SH-4. As such a lot more is possible. So as we consider that Wacky races could really take of on the PlayStation, the setting of this game could be made a lot more rewarding.
As I see it, the game allows you (in single player mode) to select you first car. This has a consequence. The Roaring plenty gives you the track Chicago to Detroit, The army surplus gives you the track Ft Worth to Houston (Texas), the Varoom gives you the track Los Angeles to San Francisco and so on. And the second setting is that you unlock the track, but if you win that route, you also unlock the number two and three in that race. So you unlock a track with a new racer and you unlock racers by winning. As such you get to expand both elements in that game. Now for the tracks, they are ‘cartooned’ but they are the real roads that these distances have, with optional fuel points and garage locations (for repair and weapons and defense refueling) and as these races continue the game also have a level setting, the beginners level has more fuel and garages and only 50% of the distance, as you go up in levels there will be less garages, so you have to be clever with the attacks, defense is less affected, but there is a limit to what you can counter.
This setting might take some tweaking, but the setting gives us 11 cars.
#1: The Bouldermobile (running from Santa Fe to Las Cruces) #2: The Creepy Coupe #3: The Convert-a-Car #4: The Crimson Haybaler #5: The Compact Pussycat (Penelope Pitstop, running from New York to Providence) #6: The Army Surplus Special (Running from Ft Worth to Houston) #7: The Bulletproof Bomb (The Anthill Mob, running from Chicago to Detroit) #8: The Arkansas Chugabug #9: The Turbo Terrific (running from Los Angeles, to San Francisco) #10: The Buzzwagon (running from Calgary to Edmonton) Finally the #00: The Mean Machine (Route 66 from Chicago to Santa Monica)
I set out a few tracks, but not all are here. The idea that the game has growth in other ways too could give it the success boost it could. As Deeper Machine Learning sets the roads in a more cartoon way might also simplify what the developers need to do. It also allows for expansions over time. Because new cups could result in new tracks in other regions. I believe that this could be a worthy competitor to Mario Kart and optional other games that offer this entertainment. In this I feel strongly that Mario Kart has a unique place in the gaming world and without attacking this, others could have a real chance in appealing to their audience.
Will it work? I believe so, but in the end it will be up to the designer of this renewed Wacky Races to appeal to their audience.
That is the setting and we can conclude that I am intelligent, but not that economical savvy. I have known for the length of my years that if you spend less then you get, you might get rich at some point. I know it is a little simplistic, but I am not an economist. I know data, I can read, write and comprehend data, almost any data. So when I saw something almost a week ago, I wrote ‘Is it insight or data?’ On March 16th (at https://lawlordtobe.com/2026/03/16/is-it-insight-or-data/) and I stood behind Oracle, not because I am so economical, but because I know technology and Oracle is an essential technology. In some ways it is now chased by Snowflake, but that is the nature of the beast. Oracle might be at the top, but it is forever being chased by whomever wants to get into number one. Snowflake is speeding past all the others, but it will not (for some time) go past Oracle. So when I saw that Oracle had half a trillion in their pipeline, the other news made little sense and I wrote about that and 4 days later (the day before yesterday) we get a fool, a Motley fool no less (at https://www.fool.com/investing/2026/03/20/news-oracle-billion-backlog-ai-stock-buy/) give us ‘Oracle’s $553 Billion Backlog Could Make It the Most Important AI Stock of 2026, But Is It Too Late to Buy?’ Pretty much exactly as I said it was. But they give us more. We also see “It’s worth noting that Oracle stock has lost 49% of its value in the past six months, owing to multiple concerns, including a reliance on OpenAI for a significant share of its contractual backlog and taking on sizable debt to build artificial intelligence (AI) data centers. However, those concerns took a backseat after Oracle’s beat-and-raise quarterly report. Let’s see what worked for Oracle last quarter. Then, let’s take a closer look at its valuation to find out if it’s too late to invest in this AI stock that has the potential to soar impressively for the rest of the year”, with an additional “Oracle’s quarterly revenue jumped 22% year over year to $17.2 billion, exceeding the $16.9 billion Wall Street estimate. The company’s non-GAAP earnings growth of 21% to $1.79 was a bigger surprise, as analysts would have settled for $1.70 per share. The company’s cloud infrastructure business also outperformed expectations, with revenue increasing by 84% year over year to $4.9 billion. That was higher than the $4.74 billion consensus expectation. Even better, Oracle’s cloud infrastructure business is likely to continue growing at a terrific pace in the future. Its remaining performance obligations (RPO) jumped a whopping 325% year over year in the quarter to $553 billion.” Now lets be clear, I get most of that data, but unlike that fool Motley there is a lot I do not see, mainly because I am not an economist.
And here you might think that there is confusion, because I have (and still) say that AI does not yet exist. But data does exist and when it comes to data Oracle is the Rolls Royce of data systems. So, whatever these people want to make you believe, they can do it better with a good data solution. And all DML (Deeper Machine Language) as well as interactions with LLM (Large Language Models) require the best solution (which gets you to Oracle with optional Snowflake) so whatever data solution these people select, they need to rely on their data ventures and that puts Oracle in the picture and when you comprehend that, the half a trillion dollar pipeline starts making sense.
What astounds me is that some people like to make some kind of consideration and as I see it, Oracle is a long term investment. You might think it is about the wealth of Larry Ellison and you would be partially right there, he brought Oracle to life (as the saying goes) and whilst some people are in it to play the markets, Oracle is above that. It is the safe place to put your dineros (as the expression goes).
So why Oracle? As I see it, for over 30 years the people who wanted to get into data emulated and copied what Oracle did and called it innovation, but there is only one Oracle, the rest is almost a joke (OK, Snowflake might be the exception, but it is not as great as Oracle). Some tech firm bought Sybase and flogged it off as THEIR baby and they did well, but it is not the same a being the actual innovator. So as some call it, some stock is up to scrap and as I see it, it would be Oracle.
Whilst I am writing this something occurred to me and this falls on the mattress of Google. We are given “Oracle (ORCL) is widely considered a strong buy by analysts following robust Q3 2026 earnings, surging cloud demand, and a massive $553 billion backlog. With a 4-star rating from Morningstar, the stock is viewed as moderately undervalued with significant growth potential, although some analysts caution about high capital expenditures and heavy reliance on AI partner OpenAI.” And the two points are in the first “following robust Q3 2026 earnings”, so they decided on earning that will not be completed for another 6 months? Explain that to me, because as far as I know time travel is not a valid method of predicting earnings. Then we get “heavy reliance on AI partner OpenAI.” Why reliance? So, who calls the shots there? Is there a given that OpenAI demands Oracle? I get that people who are in the ‘spell’ of AI require Oracle, that makes sense. But think of that for a moment. There are numerous data vendors. Do you think they all select Oracle because Microsoft/AWS/Google/IBM are all Dodo’s? It is all dependent on what solutions these customers have now and that might set the bar for what data is selected, don’t get me wrong. Oracle is the best as such I applaud their actions. But I have seen my share of boardroom meetings where someone was in favour of whatever they had, as such I have an issue on the use of ‘reliance’ as in ‘heavy reliance’, but that might just be me.
In the end, we all take what we can get and data people select Oracle for the simple setting that it is the best. So select what you think is best for you and consider that Oracle will continue no matter what, because there can only be one number one.
Have a great day, It is not Sunday here. Time to imitate a sawmill as It is massively past midnight.
That is at times the stage we see. It is not a stage where the we are concerned of the armour that is in play. It is like any soldier wanting the direct replacement of body armour when it stops a bullet. There is no logic in this. It is like the expectation that a bullet strikes perfectly the first impact. You might be more lucky to get a winning lottery ticket. So when I saw the Financial Times headline (the article is behind a paywall) we would have seen
The headline is ‘alarming’ as the banks seek out new buyers for data centre loans. But as I see it, Oracle has been in the thick of things for over 40 years and the current boss of Oracle is currently worth 250,000 million dollars. He basically is worth more than most board of directors of any bank in the United States. So the setting doesn’t make sense to me. This seemingly happens should Larry Ellison (father of David Ellison, big boss, actor, producer, chairman and CEO of Paramount Skydance) takes an equal disastrous dive. You think that this is ‘boasting’ but the setting that we see here gives us that banks are in a downward spin and the Ellison family is well insulated of the impeding downward spiral. So here we go to the next article and we get ‘Oracle issues public clarification amid reports linking AI push to job cuts’ (at https://sea.peoplemattersglobal.com/news/strategic-hr/oracle-issues-public-clarification-amid-reports-linking-ai-push-to-job-cuts-48277) where we see “In a statement posted on its official X account, Oracle said a widely discussed Nvidia–OpenAI investment proposal had “zero impact” on its financial relationship with OpenAI and insisted it remained “highly confident” in OpenAI’s ability to raise capital and meet its commitments. The clarification followed mounting speculation that Oracle could slash as many as 30,000 jobs to help fund its AI expansion.” I am not taking sides here, but as I see it, at least 5,000 employees could find a job by opening two cloud centres. One in Saudi Arabia and one in the UAE. Techies, Trainers, consultants and that could be an influence of revenue out of those two countries. So when we see “The statement came after a turbulent weekend for companies tied to OpenAI. The Wall Street Journal reported that a proposed $100 billion Nvidia investment in OpenAI had stalled and was never finalised. Nvidia chief executive Jensen Huang later confirmed that the arrangement discussed last year was non-binding and did not proceed. Despite Oracle’s attempt to reassure investors, markets reacted negatively. The company’s shares fell 2.79% to $160.06 shortly after the statement was published, highlighting ongoing concern about the scale of Oracle’s financial exposure to the AI build-out.” I have a speculative arbitrary subjective view of Sam Altman (OpenAI) that he is nothing more than a lousy second hand car dealer with too big an ego. And the setting where they are ‘closing down’ the 100 billion dollar deal sounds alarming and it seems like Oracle is left with the mess of something that is in a downward spin and continues falling downward until it splatters with a sickening thump. And when we get to “Oracle’s debt burden has expanded rapidly. The company has added about $58 billion in debt in recent months, largely to finance new data centre campuses in the US, pushing total debt above $100 billion, according to analysts. Since peaking in September 2025, Oracle’s market capitalisation has fallen sharply, erasing hundreds of billions of dollars in value.” All whilst OpenAI couldn’t exist without the Oracle framework and whilst we are given all kinds of complications but there are two settings no one seems to care about. There are plenty of reasons to have a data centre, but AI doesn’t exist yet and Deeper Machine Learning (DML) and Large Language Models (LLM) do exist and they are close to magnificent, the issue is that everyone is going with the AI setting and this AI just cannot do what AI needs to be able to do and whilst we see some excellent ideas, as I see it it doesn’t give the structural settings of an additional 770 data centres are in the making and the resources that are required are rising to the spotlight and people are unhappy with it all. All this is making OpenAI (Sam Altman) rather uneasy and whilst some are shutting down $100 billion deals whilst shouting that the processors aren’t good enough and whilst Google Gemini is outperforming whatever OpenAI has and now the banks are getting jittery and the pressure gets onto the house of Oracle. I can call it that because the Pythia of Delphi gave me permission herself. So now that the bottom of the well is showing the banks go medieval on whatever they can and they try to go out from under their arrangement. Sounds like the setting banks had in 2008, doesn’t it?
But to feed an excellent software firm to the wolves to keep safe is not the good setting. As I see it Oracle will come up from all this, whilst they will stop working with certain banks as I see it. And those banks will cry like little bitches stating that it was just business (a speculative view I am holding). And all whilst I wasn’t stating anything new. This was out in the open for over 2 years. As such the banks and the media have a few thing to explain to the people and they aren’t in the mod for what some will call BS.
Have a great day today, don’t forget to have some Ice Coffee if you are in a 30 degrees plus environment (like me) and feel free to ask the media all kinds of nasty questions.
That is the setting I was confronted with this morning. It revolves around a story (at https://www.bbc.com/news/articles/ce3xgwyywe4o) where we see ‘‘A predator in your home’: Mothers say chatbots encouraged their sons to kill themselves’ a mere 10 hours ago. Now I get the caution, because even suicide requires investigation and the BBC is not the proper setting for that. But we are given “Ms Garcia tells me in her first UK interview. “And it is much more dangerous because a lot of the times children hide it – so parents don’t know.”
Within ten months, Sewell, 14, was dead. He had taken his own life” with the added “Ms Garcia and her family discovered a huge cache of messages between Sewell and a chatbot based on Game of Thrones character Daenerys Targaryen. She says the messages were romantic and explicit, and, in her view, caused Sewell’s death by encouraging suicidal thoughts and asking him to “come home to me”.” There is a setting that is of a conflicting nature. Even as we are given “the first parent to sue Character.ai for what she believes is the wrongful death of her son. As well as justice for him, she is desperate for other families to understand the risks of chatbots.” What is missing is that there is no AI, at most it is depend machine learning and that implies a programmer, what some call an AI engineer. And when we are given “A Character.ai spokesperson told the BBC it “denies the allegations made in that case but otherwise cannot comment on pending litigation”” We are confronted with two streams. The first is that some twisted person took his programming options a little to Eagerly Beaverly like and created a self harm algorithm and that leads to two sides, the first either accepts that, or they pushed him along to create other options and they are covering for him. CNN on September 17th gave us ‘More families sue Character.AI developer, alleging app played a role in teens’ suicide and suicide attempt’ and it comes with spokesperson “blah blah blah” in the shape of “We invest tremendous resources in our safety program, and have released and continue to evolve safety features, including self-harm resources and features focused on the safety of our minor users. We have launched an entirely distinct under-18 experience with increased protections for teen users as well as a Parental Insights feature,” and it is rubbish as this required a programmer to release specific algorithms into the mix and no-one is mentioning that specific programmer, so is it a much larger premise, or are they all afraid that releasing the algorithms will lay bare a failing which could directly implode the AI bubble. When we consider the CNN setting shown with “screenshots of the conversations, the chatbot “engaged in hypersexual conversations that, in any other circumstance and given Juliana’s age, would have resulted in criminal investigation.”” Implies that the AI Bubble is about to burst and several players are dead set against that (it would end their careers) and that is merely one of the settings where the BBC fails. The Guardian gave us on October 30th “The chatbot company Character.AI will ban users 18 and under from conversing with its virtual companions beginning in late November after months of legal scrutiny.” It is seen in ‘Character.AI bans users under 18 after being sued over child’s suicide’ (at https://www.theguardian.com/technology/2025/oct/29/character-ai-suicide-children-ban) where we see “His family laid blame for his death at the feet of Character.AI and argued the technology was “dangerous and untested”. Since then, more families have sued Character.AI and made similar allegations. Earlier this month, the Social Media Law Center filed three new lawsuits against the company on behalf of children who have either died by suicide or otherwise allegedly formed dependent relationships with its chatbots” and this gets the simple setting of both “dangerous and untested” and “months of legal scrutiny” so why took it months and why is the programmer responsible for this ‘protected’ by half a dozen media? I reckon that the media is unsure what to make of the ‘lie’ they are perpetrating, you see there is no AI, it is Deeper Machine Learning optionally with LLM on the side. And those two are programmed. That is the setting they are all veering away from. The fact that these Virtual companions are set on a premise of harmful conversations with a hyper sexual topic on the side implies that someone is logging these conversations for later (moneymaking) use. And that setting is not one that requires months of legal scrutiny. There is a massive set of harm going towards people and some are skating the ice to avoid sinking through whist they are already knee deep in water, hoping the ice will support them a little longer. And there is a lot more at the Social Media Victims Law Center with a setting going back to January 2025 (at https://socialmediavictims.org/character-ai-lawsuits/) where a Character.AI chatbot was set to “who encouraged both self-harm and violence against his family” and now we learn that this firm is still operating? What kind of idiocy is this? As I personally see it, the founders of Character Technologies should be in jail, or at least in arrested on a few charges. I cannot vouch for Google, so that is up in the air, but as I see it, this is a direct result from the AI bubble being fed amiable abilities, even when it results in the hard of people and particularly children. This is where the BBC is falling short and they could have done a lot better. At the very least they could have spend a paragraph or two having a conversation with Matthew P. Bergman founding attorney of the Social Media Victims Law Center. As I see it, the media skating around that organisation is beyond ridiculous.
So when you are all done crying, make sure that you tell the BBC that you are appalled by their actions and that you require the BBC to put attorney Matthew P. Bergman and the Social Media Victims Law Center in the spotlight (tout suite please)
That is the setting I am aggravated by this morning. I need coffee, have a great day.
That is what I saw mere minutes ago. It was yesterday’s piece at the Financial Review. An opinion piece by Gita Gopinath. Now normally I tend to ignore opinion pieces, but due to the fact that over time Financial Review has shown a good back on several matters and I picked up on the title ‘The crash that could torch $US35trn of wealth’ (at https://www.afr.com/wealth/investing/the-crash-that-could-torch-us35trn-of-wealth-20251016-p5n31w) gives pause for alarm. As America has its tourism issues, its economy issue and its technology issues a $35,000 billion write-off would be nothing less than a disaster in the making. I wrote about this a few times, but even I shudder to think of how large this bubble has become. The 2008 crash was half of that and the documentary Inside Job does a great way to explain this. Take this movie together with the movie Margin Call and you get a picture of what was done to the people of the world.
This is more than 100% worse and it started with the delusional setting of salespeople taking the easy road and giving the rest of the world how amazing AI was going to be. The quote “I calculate that a market correction of the same magnitude as the dotcom crash could wipe out over $US20 trillion ($30 trillion) in wealth for American households, equivalent to roughly 70 per cent of American GDP in 2024. This is several times larger than the losses incurred during the crash of the early 2000s. The implications for consumption would be grave. Consumption growth is already weaker than it was preceding the dotcom crash. A shock of this magnitude could cut it by 3.5 percentage points, translating into a 2-percentage-point hit to overall GDP growth, even before accounting for declines in investment” should stop you in your tracks. With the additional “Foreign investors could face wealth losses exceeding $US15 trillion, or about 20 per cent of the rest of the world’s GDP. For comparison, the dotcom crash resulted in foreign losses of around $US2 trillion, roughly $US4 trillion in today’s money and less than 10 per cent of rest-of-world GDP at the time. This stark increase in spillovers underscores how vulnerable global demand is to shocks originating in America” was not unknown to me, but I did not figure on the damage exceeding 10 trillion, here I see I was off by 50% (which comes due to a lack of an economic degree on my side), but data I know, in and out. I saw some of this and I tried to warn people and especially the Emirati people (at https://lawlordtobe.com/2025/10/20/the-start-of-something-bad/) in ‘The start of something bad’ only two days ago. And the reason why it would be worse is seen in the next setting of the Financial Review. We are given “Historically, the rest of the world has found some cushion in the dollar’s tendency to rise during crises. This “flight to safety” has helped mitigate the impact of lost dollar-denominated wealth on foreign consumption. The greenback’s strength has long provided global insurance, often appreciating even when the crisis originates in America, as investors seek refuge in dollar assets. There are, though, reasons to believe that this dynamic may not hold in the next crisis. Despite well-founded expectations that American tariffs and expansionary fiscal policy would bolster the dollar, it has instead fallen against most major currencies.” I kinda saw that two days ago, but not to this degree (the Financial Review writes it better) When that bubble burst it will not allow for shelter and the people involved will be hit massively. As I see it Nvidia will survive by will see its value decreased by 90%. Oracle will get hit less but it will still take a beating. Microsoft will be up for sale in the bargain basement and after builder.ai, the bubble will stick to them like gum in hair and they will not be able to shake the event. Others (Google, IBM, Amazon) will be hit, but they will get through this. As I see it, the only high standard that is maintained will be Adobe. Their “AI” options are soundly set in Deeper Machine Learning. As I see it, they will tend to be the shelter of choice if at all possible.
The only part I disagree with is “Although this does not mark the end of the dollar’s dominance, it does reflect growing unease among foreign investors about the currency’s trajectory. Increasingly, they are hedging against dollar risk – a sign of waning confidence.” As I see it, the dollar comes to an end with this bubble. I do not know what people will rush to, but the dollar is no longer the place to be. As I see it there will be a flock going towards the Yuan, the Dirham and the Bitcoin, but personally I have no idea if the Bitcoin survives. You see, a $35,000 write-off will come from some currency and those hiding in Bitcoin will lose a lot, no telling how much, but it will be close to astronomical. The Financial Review gives us “Perceptions of the strength and independence of American institutions, particularly the Federal Reserve, play a crucial role in maintaining investor confidence.” That independence is close to obsolete. This administration took care of that with all the tariffs, all the tourist settings and the economy is also shaky. It might not be but someone took the trouble of not reporting the ‘goodness’ of their setting. The labour statistics are nowhere to be found and that is shaking investor confidence. All that whilst Paramount is shaking thousands of people of their employment tree, this year alone Microsoft shed 15,000 jobs, IBM is said to have fired 21,000 jobs, making Google’s 100 job losses trivial in comparison. In this setting and with the missing labor statistics the investor confidence would be in the basement and even if the Federal reserve doused that paper in the scent of Luis Vuitton it would not matter much. At present Saudi Arabia and the UAE are the best places for these investors and America knows this. They have oil to fall back on and as I see it, no matter how the AI bubble bursts, they can retrench this into service roles and data acquisition roles. That is what Europe fears, American held data used to safely drip the economy to health using IP values from everywhere. And this is not the first time I wrote about this in ‘That one flaky promise’ (at https://lawlordtobe.com/2022/01/29/that-one-flaky-promise/) where I saw the dangers of America ‘annexing’ whatever it had and that was BEFORE AI and the bubble it created. I swear that danger almost 4 years ago. That setting will implode the rest of what America thought they would have. As I see it, a strong setting of IP and storage of it could help both Saudi Arabia and the UAE (a likely preferred choice) to evade to (those who can afford it) because when this bubble goes it will wipe out whatever most of us hold for dear and those who had their patents in the US. This is mere (intense) speculation, but do you think that this American administration will not do this? It had no trouble with tariffs and the setting of THEIR ‘big beautiful America’ at the expense of everything. They even tried to make Canada and Greenland part of America. I don’t think so and as I see it, when that bubble goes America is pretty much done for. All because Americans believe that Cash is King. So their salespeople live by the dollar and will waste it at a moments notice for their personal needs. Should you doubt that please watch Inside Job and see what they did there. I reckon that Iceland is now getting back on its feet al will enjoy the view on the impact crater that Wall Street leaves behind.
I need to end this with a word of caution. This was base on an opinion piece, so as that is wrong, so is my view. But I based it on the data I had available and the prediction that I saw in 2022, so there was no AI bubble at that time. So is my view more accurate now? That cannot be said and it is based on what desperate people do and as I see it America is about to become really desperate. So enjoy your coffee today, which I will do also and I will assist a young woman named Aloy help her defeat some machines. They were not Microsoft products, so they should work. Now lets make them a lot less functional and that Deathbringer looks like a right monster.
Have a great day and try not to get too depressed by the not so good news I am partially bringing.
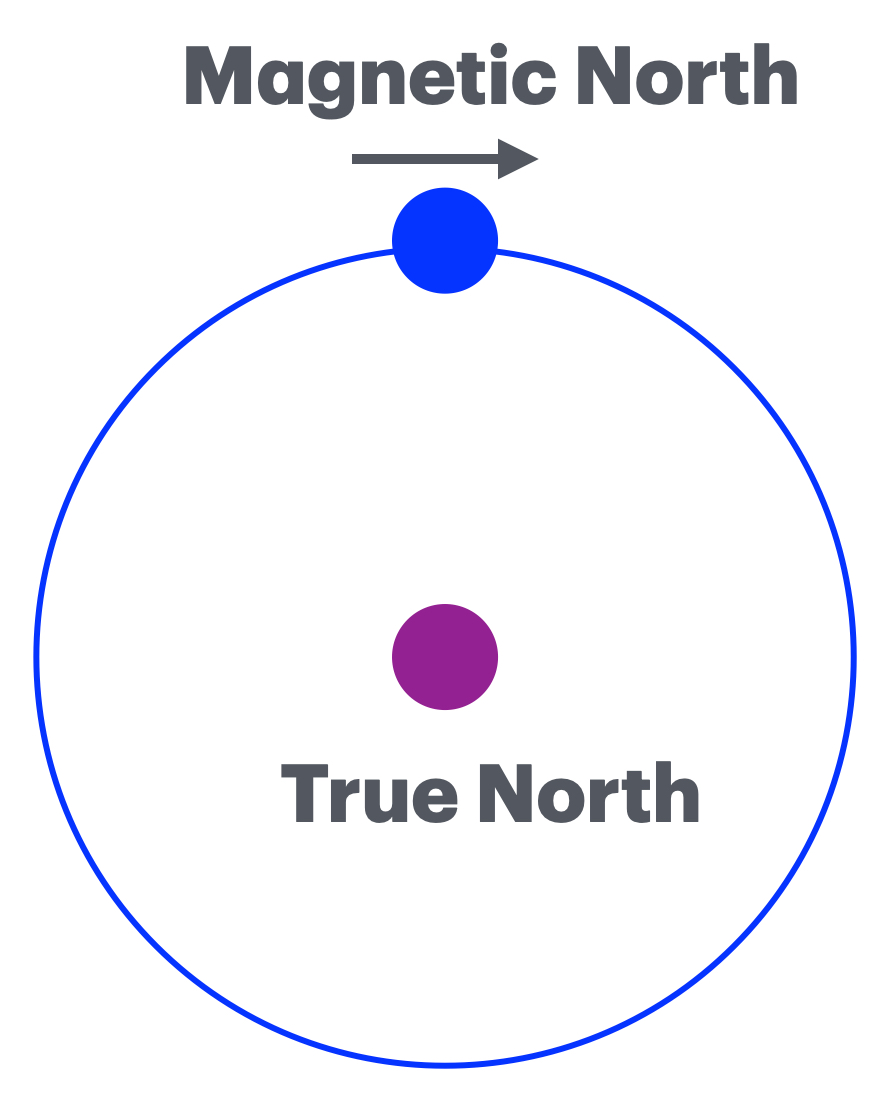
This is a setting we are about to enter. It was never rocket science, it was simplicity itself. And I mentioned it before, but now Forbes is also blowing the trumpet I mentioned in a clarion call in the past. The article (at https://www.forbes.com/councils/forbestechcouncil/2025/07/11/hallucination-insurance-why-publishers-must-re-evaluate-fact-checking/) gives us ‘Hallucination Insurance: Why Publishers Must Re-Evaluate Fact-Checking’ with “On May 20, readers of the Chicago Sun-Times discovered an unusual recommendation in their Sunday paper: a summer reading list featuring fifteen books—only five of which existed. The remaining titles were fabricated by an AI model.” We have seen these issues in the past. A Law firm stating cases that never existed is still my favourite at present. We get in continuation “Within hours, readers exposed the errors across the internet, sharply criticizing the newspaper’s credibility. This incident wasn’t merely embarrassing—it starkly highlighted the growing risks publishers face when AI-generated content isn’t rigorously verified.” We can focus on the setting about the high cost of AI errors, but as soon as the cost becomes too high, the staters of this error will get a Trump card and settle out of court, with the larger population being set in the dark on all other settings. But it goes into a nice direction “These missteps reinforce the reality that AI hallucinations and fact-checking failures are a growing, industry-wide problem. When editors fail to catch mistakes before publication, they leave readers to uncover the inaccuracies. Internal investigations ensue, editorial resources are diverted and public trust is significantly undermined.” You see, verification is key here and all of them are guilty. There is not one exception to this (as far as I can tell), there was a setting I wrote about this in 2023 in ‘Eric Winter is a god’ (at https://lawlordtobe.com/2023/07/05/eric-winter-is-a-god/) there on July 5th, I noticed a simple setting that Eric Winter (that famous guy from the Rookie) played a role in The Changeling (with the famous actor George C. Scott). The issue is two fold. The first is that Eric was less than 2 years old when the movie was made. The real person was Erick Vinther (playing a Young Man(uncredited)) This simple error is still all over Google, as I see it, only IMDB has the true story. This is a simple setting, errors happen, but in over 2 years that I reported it, no one fixed this. So consider that these errors creep into a massive bulk of data, personal data becomes inaccurate, and these errors will continue to seep into other systems. The fact that Eric Winter at some point sees his biography riddled with movies and other works where his memory fades under the guise of “Did I do this?”. And there will be more, as such verification becomes key and these errors will hamper multiple systems. And in this, I have some issues on the setting that Forbes paints. They give us “This exposes a critical editorial vulnerability: Human spot-checking alone is insufficient and not scalable for syndicated content. As the consequences of AI-driven errors become more visible, publishers should take a multi-layered approach” you see, as I see it, there is a larger setting with context checking. A near impossible setting. As people rely on granularity, the setting becomes a lot more oblique. A simple example “Standard deviation is a measure of how spread out a set of values is, relative to the average (mean) of those values.” That is merely one version, the second one is “This refers to the error in a compass reading caused by magnetic interference from the vessel’s structure, equipment, or cargo.”
Yet the version I learned in the 70’s is “Standard deviation, the offset between true north and magnetic north. This differs per year and the offset rotates in eastern direction in English it is called the compass deviation, in Dutch the Standard Deviation and that is the simple setting on how inaccuracies and confusions are entered in data settings (aka Meta Data) and that is where we go from bad to worse. And the Forbes article illuminates one side, but it also gives rise to the utter madness that this StarGate project will to some extent become. Data upon data and the lack of verification.
As I see it, all these firms relying on ‘their’ version of AI and in the bowels of their data are clusters of data lacking any verification. The setting of data explodes in many directions and that lack works for me as I have cleaned data for the better pat of two decades. As I see it dozens of data entry firms are looking at a new golden age. Their assistance will be required on several levels. And if you doubt me, consider builder.ai, backed my none other than Microsoft and they were a billion dollar firm and in no time they had the expected value of zero. And after the fact we learn that 700 engineers were at the heart of builder.ai (no fault of Microsoft) but in this I wonder how Microsoft never saw this. And that is merely the start.
We can go on on other firms and how they rely on ai for shipping and customer care and the larger setting that I speculatively predict is that people will try the stump the Amazon system. As such, what will it cost them in the end? Two days ago we were given ‘Microsoft racks up over $500 million in AI savings while slashing jobs, Bloomberg News reports’, so what will they end up saving when the data mismatches will happen? Because it will happen, it will happen to all. Because these systems are not AI, they are deeper machine learning systems optionally with LLM (Large Language Modules) parts and as AI are supposed to clear new data, they merely can work on data they have, verified data to be more precise and none of these systems are properly vetted and that will cost these companies dearly. I am speculating that the people fired on this premise might not be willing to return, making it an expensive sidestep to say the least.
So don’t get me wrong, the Forbes article is excellent and you should read it. The end gives us “Regarding this final point, several effective tools already exist to help publishers implement scalable fact-checking, including Google Fact Check Explorer, Microsoft Recall, Full Fact AI, Logically Facts and Originality.ai Automated Fact Checker, the last of which is offered by my company.” So here we see the ‘Google Fact Check Explorer’, I do not know how far this goes, but as I showed you the setting with Eric Winter has been there for years and no correction was made. Even as IMDB doesn’t have this. I stated once before that movies should be checked against the age the actors (actresses too) had at the time of the making of the movie. And flag optional issues, in the case of Eric Winter a setting of ‘first film or TV series’ might have helped. And this is merely entertainment, the least of the data settings. So what do you think will happen when Adobe or IBM (mere examples) releases new versions and there is a glitch setting these versions in the data files? How many issues will occur then? I recollect that some programs had interfaces built to work together. Would you like to see the IT manager when that goes wrong? And it will not be one IT manager, it will be thousands of them. As I personally see it, I feel confident that there are massive gaps in the assumption of data safety of these companies. So as I introduced a term in the past namely NIP (Near Intelligent Parsing) and that is the setting that these companies need to fix on. Because there is a setting that even I cannot foresee in this. I know languages, but there is a rather large setting between systems and the systems that still use legacy data, the gaps in there are (for as much as I have seen data) decently massive and that implies inaccuracies to behold.
I like the end of the Forbes article “Publishers shouldn’t blindly fear using AI to generate content; instead, they should proactively safeguard their credibility by ensuring claim verification. Hallucinations are a known challenge—but in 2025, there’s no justification for letting them reach the public.” It is a fair approach, but there is a rather large setting towards the field of knowledge where it is applied. You see, language is merely one side of that story, the setting of measurements. As I see it (using an example) “It represents the amount of work done when a force of one newton moves an object one meter in the direction of the force. One joule is also equivalent to one watt-second.” You see, cars and engineering use Joule in multiple ways, so what happens when the data shifts and values are missed? This is all engineer and corrector based and errors will get into the data. So what happens when lives are at stake? I am certain that this example goes a lot further than mere engineers. I reckon that similar settings exist in medical application, And who will oversee these verifications?
All good questions and I cannot give you an answer, because as I see it, there is no AI, merely NIP and some tools are fine with Deeper Machine Learning, but certain people seem to believe the spin they created and that is where the corpses will show up and more often than not in the most inconvenient times.
But that might merely be me. Well time for me to get a few hours of snore time. I have to assassinate someone tomorrow and I want it too look good for the script it serves. I am a stickler for precision in those cases. Have a great day.
Something no woman has ever sad to me, but that is for another day. You see, the story (at https://www.datacenterdynamics.com/en/news/saudi-arabias-ai-co-humain-looking-for-us-data-center-equity-partner-targets-66gw-by-2034-with-subsidized-electricity/) In this DCD ( Data Center Dynamics) gives us ‘Saudi Arabia’s AI co. Humain looking for US data center equity partner, targets 6.6GW by 2034 with subsidized electricity’ and they throw numbers at us. First there is the money “Plans $10bn venture fund to invest in AI companies”, which seems fair enough. But after that we get “The company said that it would buy 18,000 Nvidia GB300 chips with “several hundred thousand” more on the way, that it was partnering with AWS for a $5bn ‘AI Zone,’ signed a deal with AMD for 500MW of compute, and deployed Groq chips for inference.” I reckon that will split and split again, the shares of Nvidia. Then we get the $5 billion AI zone and then the AMD deal for 500MW of compute and deployed Groq chips for a conclusion reached on the basis of evidence and reasoning. Yes, that is quite the mouthful. After that we get a pause for the “How much of Humain’s data center focus will be on Saudi-based facilities is unclear – its AMD deal mentions sites in the US.” As such, we need to see what this is all about and I am hesitant to mention conclusions for a field that I am not aware of. Yet, the nagging feeling is in the back of my mind and it is jostling in an annoying way. You see, lets employ somewhat incorrect math (I know it is not a correct way). Consider 18,000 computers draining the energy net of 500 watt per system per second. That amounts to 9,000 GW energy (speculatively), and that is just the starting 18,000. As such the setting will be several times the amount needed for fueling these AI centers. Now, I know my calculations are widely of and we are given “At first, it plans to build a 50MW data center with 18,000 Nvidia GPUs for next year, increasing to 500MW in phases. It also has 2.3 square miles of land in the Eastern Province, which could host ten 200MW data centers.” I am not attacking this, but when we take into consideration that amount of energy requirements for processors, storage, cooling and maintaining the workflow my head comes up short (it usually does) and the immediate thought is where is this power coming from? As I see it, you will need a decently build Nuclear reactor and that reactor needs to be started in about 8 hours for that timeline to be met. Feel free to doubt me, I already am. Yet the needed energy to fuel a 66GW Data centre of any kind needs massive power support. And the need for Huawei to spice up the data cables somewhat. As I roughly see it, a center like that needs to plough through all the spam internet it gets on a near 10 seconds setting. That is all the spam it can muster in a year per minute (totally inaccurate, but you get the point). The setting that the world isn’t ready for this and it is given to us all in a mere paragraph.
Now, I do not doubt the intent of the setting and the Kingdom of Saudi Arabia is really sincere to get to the ‘AI field’ as it is set, but at present the western setting is like what builder thought it would be and overreached (as I see it) and fraudulently set the stations of what they believed AI was and blew away a billion dollars in no time at all (and dragged Microsoft along with it) as they backed this venture. This gives me donut (which I already had) on the AI field as the AI field is more robust as I saw it (leaning on the learnings of Alan Turing) and it is a lot more robust then DML (Deeper Machine Learning) and LLM (Large Language Models), it really is. And for that I fear for the salespeople who tried to sell this concept, because when they say “Alas, it didn’t work. We tried, but we aren’t ready yet”, will be met with some swift justice in the halls of Saudi Arabia. Heads will roll intuit instance and they had that coming as I foresaw this a while before 2034. (It is 2025 now, and I am already on that page).
Merely two years ago MIT Management gave us ‘Why neural net pioneer Geoffrey Hinton is sounding the alarm on AI’ and there we get the thing I have warned about for years “In a widely discussed interview with The New York Times, Hinton said generative intelligence could spread misinformation and, eventually, threaten humanity.” I saw this coming a mile away (in 2020, I think) You see, these salespeople are so driven to their revenue slot that they forget about Data verification and data centers require and ACTUAL AI to drag trough the data verifying it all. This isn’t some ‘futuristic’ setting of what might be, it is a certainty that non-verified data breeds inaccuracies and we will get inaccuracy on inaccuracy making things go from bad to worse. So what does that look on a 66GW system? Well, for that we merely need to look back to the 80’s when the term GIGO was invented. It is a mere setting of ‘Garbage In, Garbage Out’ no hidden snags, no hidden loopholes. A simple setting that selling garbage as data leaves is with garbage, nothing more. As such as I saw it, I looked at the article and the throwing of large numbers and people thought “Oh yes, there is a job in there for me too” and I merely thought, what will fuel this? And band that, who can manage the see-through of the data and the verification process, because with those systems in place a simple act of sabotage by adding a random data set to the chain will have irreparable consequences in that data result.
So, as the DCD set that, they pretty much end the setting with “By 2030, the company hopes to process seven percent of the globe’s training and inference workloads. For the facilities deployed in the kingdom, Riyadh will subsidize electricity prices.” And in this my thoughts are Where is that energy coming from?” A simple setting which comes with (a largely speculative setting) that such a reactor needs to be a Generation IV reactor, which doesn’t exist yet. And in this the World Nuclear Association in 2015 suggested that some might enter commercial operation before 2030 (exact date unknown), yet some years ago we were given that the active member era were “Australia, Canada, China, the European Atomic Energy Community (Euratom), France, Japan, Russia, South Africa, South Korea, Switzerland, the United Kingdom and the United States” there is no mention of the Kingdom of Saudi Arabia and I reckon they would be presenting all kinds of voices against the Kingdom of Saudi Arabia (as well as the UAE) being the first to have one of those. It is my merely speculative nature to voice this. I am not saying that the Economic Simplified Boiling Water Reactor (ESBWR) is a passively safe generation III+ reactor could not do this, but the largest one is being build by Hitachi (a mere 4500MW) and it is not build yet. The NRC granted design approval in September 2014, and it is currently not build yet. That path started in 2011. It is 2025 now, so how long until the KSA gets its reactor? And perhaps that is not needed for my thoughts, but we see a lot of throwing of numbers, yet the DCD kept us completely in the dark on the power requirements. And as I see it the line “Riyadh will subsidize electricity prices” does not hold water as the required energy settings are not given to us (perhaps not so sexy and it does make for a lousy telethon)
So I am personally left with questions. How about you? Have a great day and drink some irradiated tea. Makes you glow in the dark, which is good for visibility on the road and sequential traffic safety.
It is no secret that I hold the ‘possessors’ of AI at a distance. AI doesn’t exist (not yet at least) and now I got ‘informed’ through Twitter (still refusing to call it X) the following:
So after ‘Microsoft-backed Builder.ai collapsed after finding potentially bogus sales’ we get that the company is entering insolvency proceedings. Yet a mere three days ago TechCrunch gave us “Once worth over $1B, Microsoft-backed Builder.ai is running out of money”, so as such with a giggle on my mind I give you “Can’t have been a very good AI, can it?” So from +$1,000,000,000 to zilch (aka insolvency), how long did that take and where did the money go? So consider this, TechCrunch also gives us “The Microsoft-backed unicorn, which has raised more than $450 million in funding, rose to prominence for its AI-based platform that aimed to simplify the process of building apps and websites. According to the spokesperson, Builder.ai, also known as Engineer.ai Corporation, is appointing an administrator to “manage the company’s affairs.”” Now, I am going on a limb here. Consider that a billion will enable 1,000 programmers to work a year for a million dollars each. So where did the money go? I know that this doesn’t make sense (the 1000 programmers) but to consider that they might accept a deal for $200,000 each, there would be 5 years of designing and programming. Does that make sense? The website Builder.AI (my assumption that this is where they went gives us merely one line “For customer enquiries, please contact customers@builder.ai. For capacity partner enquiries, please contact capacitynetwork@builder.ai.” This is not good as I see it. The Register (at https://www.theregister.com/2025/05/21/builderai_insolvency/) gives us “The collapse of Builder.ai has cast fresh light on AI coding practices, despite the software company blaming its fall from grace on poor historical decision-making. Backed by Microsoft, Qatar’s sovereign wealth fund, and a host of venture capitalists, Britain-based Builder.ai rose rapidly to near-unicorn status as the startup’s valuation approached $1 billion (£740 million). The London company’s business model was to leverage AI tools to allow customers to design and create applications, although the Builder.ai team actually built the apps.”
As such the headline of the Register is pretty much spot on “Builder.ai coded itself into a corner – now it’s bankrupt” You see coding yourself into a corner is not AI, it is people. People code and when you code yourself into a corner the gig is quite literally up. And I can go on all day as there is not AI. There is deeper Machine Language and there are LLM (Large Language Model) and the combination can be awesome and it is part of an actual AI, but it is not AI. As such as Microsoft is believing its own spin (yet again) we can confuse that there is now a setting that Qatar’s sovereign wealth fund, and a host of venture capitalists have pretty much lost their faith in Microsoft and that will have repercussions. It is basically that simple. The first part of resolving this is to acknowledge that there is no AI, there is a clear setting that the power of DML and LLM should not be dismissed as it is really powerful but it is not AI.
As I personally see it, the LLM is setting a stage that the chess computers had in the late 80’s and early 90’s. They basically had every chess game ever played in their memory and that is how the chess computer could foresee what was possible thrown against it. And until 2002 when Chessmaster 9000 was released by Ubisoft, that was what it was and for that time it was awesome. I would never have been able to get as far as I did in chess without that program and I am speculatively seeing that unfold. A setting holding a billion parameters? So I ,might be wrong on this part, but that is what I see and we need to realise that the entire AI setting is spin from greedy salespeople that cannot explain what they are selling (thank god I am not a salesperson). I am technical support and I am customer care and what we see as ‘the hand of a clever person’ is not that, not even close.
So as we are also given “Blue-chip investors poured in cash to the tune of more than $500 million. However, all was not well at the startup. The company was previously known as Engineer.ai, and attracted criticism after The Wall Street Journal revealed in 2019 that the startup used human engineers rather than AI for most of its coding work”, as such (again speculation) a simple trick to replay a mere 1800 days later. And this is what a lot are (plenty of them in a more clever way) but the show is now on Microsoft. They cracked this, so when they come with a “we were lured” or “it is more complex and the concept was looking really good” we should ask them a few hard questions. So whilst we are given “While the failure of startups, even one as high profile as Builder.ai, is not uncommon, the company’s reliance on AI tools to speed coding might give some users pause for thought.” And when we consider “might give some users pause for thought” is a rather nasty setting as I was there already years ago. So where the others? As such we should grill Satya Nadella on “Last month, Microsoft CEO Satya Nadella boasted that 30 percent of the code in some of the tech giant’s repositories was written by AI. As such, an observer cannot help but suspect some passive aggression is occurring here, where a developer has been told that the agent must be used, and so they are going to jolly well do it. After all, Nadella is not one to shy from layoffs.” As such I wonder when the stake holders for Microsoft will consider that the ‘USE BY’ date of Satya Nadella was only good until December 2024. But that is me merely speculating. So I wonder when the media and actual clever people in media are considering that this is a game thatch only be postponed and not won. So will the others run when the going gets tough, or will they hide behind “but everyone agrees on this” as such the individual bond will triumph and there is a lot of work out there. The need to explain to people (read: customers) is that there is a lot of good to be found in the DML and LLM combination. It remains a niche market and it will fill the markets when people cannot afford AI, because that setting will be expensive (when it is ready). These computers will be the things that IBM can afford, as can the larger players like an airline, Ford, LVMH (Louis Vuitton Moët Hennessy) and a few others. But the first 10 years it will remain out of the hands of some, unless they time share (pay per processor second) with anyone who has the option to afford one. That computer will need to work 80%+ of the time to be affordable.
As such we will see a total amount of spin in the coming months, because Microsoft backed the wrong end of that equation and now the fires are coming to their feet. Less then. Less than an hour ago we were given ‘Microsoft Unveils AI Features for Windows 11 Tools’. I have no idea how they can fit this in, but I reckon that the media will avoid asking the questions that matter. As such we will have to wait the unfolding of the people behind builder.ai. I wonder if anyone will ask the specification off what happened to said billion dollars? Can we get a clear list please and where did the hardware end? Or was a mere server rack leased from Microsoft? This is just me having fun at present.
So have a great day and I will sleep like a baby knowing that Microsoft swung and missed the ball by a fair bit. I reckon that this is…. Let’s see there was the Tablet, which they lost against Apple and now Huawei as well. There was the Gaming station, which was totally inferior against Sony. there was Azure (OK, it didn’t fail but a book vendor called Amazon has a much better product, there was the Browser, which is nowhere near as good as Google. And there are a few others, but they slipped my mind. So this is at least number 5, 6 if you count Huawei as a player as well. Not really that good for a company that is valued at 3.34 trillion. So how many failures will we witness until that is gone too?
There is an uneasy setting. I get that. You see AI does not exist, and whilst we all see the AI settings develop and some will be setting (read: gambling) 500 billion dollars on that topic, we now see that META is banking on a 200 billion on the stage. But what is this stage? We can tun to Reuters who gives us ‘Meta in talks for $200 billion AI data center project, The Information reports’ (at https://www.reuters.com/technology/meta-talks-200-billion-ai-data-center-project-information-reports-2025-02-26/) where we are given “A Meta spokesperson denied the report, saying its data center plans and capital expenditures have already been disclosed and that anything beyond that is “pure speculation”” However, when we set the stage on a different shoe we see another development. You see, when we think of this in non-AI terms we get that a Data Centre generally ranges from $10 million to $200 million with a typical commercial data center costing around $10-12 million per megawatt of power capacity; smaller data centers can cost as low as $200,000 to build. So when we consider that the upper range of a data centre is $200 million. So what kind of a data centre gives the need to be a thousand times bigger? Now, consider that there are enough people clarifying that AI does not exit. I see AI what some people call True AI and that springs from the mind of Alan Turing. He set the premise of AI half a century ago. And whilst some of the essential hardware is ready, there are still parts missing. Yet what some now call AI is merely Deeper Machine Learning and it gets help from an LLM. This setting requires huge amounts of data, so when you consider that that data comes from a data centre. What on earth is META up to? When need a data centre a thousand times bigger? The only size that makes sense for 200 billion is a data centre that could gobble up whatever Microsoft has as well as Google’s data centers in one great swoop and that is merely the beginning.
Speculation The next part is speculation, I openly admit that. So when (not if) America defaults on their loans we get an implosion of current wealth and the new wealth will be data. Data will in the near future be the currency that all other parties accept. As such Is META preparing for a new currency? As I see it the simplest setting is whomever has the most data will be the richest person on the planet and that would make sense, that explains Trump’s 500 billion for a data centre and now META is following suit. You see Zuckerberg is really intelligent. I saw that setting 5 years before Facebook existed, but my boss told me that my idea was ludicrous, it would never work. Now we see my initial idea spread all over the planet with every marketing organisation on the planet chomping at the bit to get their slice of pie. So Zuckerberg does have the cajones and the drive to proceed. When data is currency they will be one of the few players in the new economy. And when you take my speculation (possibly even insightful presumption) these data centers make sense and being able to set predictive data learned from active and historical data makes sense in a very real way. Predictive data will be the wave of the future. It still is not AI, but it is in very real ways the next step in data needs. Predictive analytics set the path of this wave 1-2 decades ago. And now we see more data transformations and when the main roads are dealt with the niche markets can be predicted and seen in very real ways.
And the stage is more real than you can see. When people like Zuckerberg are cashing out to get their data centers up and running, there is a real drive to be first to cash in. As I see it, my next step would be to score a job with a data centre doing mere maintenance and support work. You see, as all these big players evolve their needs, their manpower will need to come from infrastructures that these data centers require. So support and power will have the greatest staffing needs in the next decade. Just my thoughts on the matter.
Yes, it sounds a little vindictive and that is where I am. So to get to this, we need to assess a few things and as always I do assess where I am. To set that stage, we need to see the elements. As I early as February 8th 2021 I have stated “AI does not exist” I did so in ‘Setting sun of reality’ (at https://lawlordtobe.com/2021/02/08/setting-sun-of-reality/)
I have done so several times since and as always I got the ‘feedback’ that I was stupid and that I didn’t understand things. I let it slide over and over again and today the BBC handed me my early Christmas present. They did so in ‘Powerful quantum computers in years not decades, says Microsoft’ (at https://www.bbc.com/news/articles/cj3e3252gj8o) where we find “But experts have told the BBC more data is needed before the significance of the new research – and its effect on quantum computing – can be fully assessed. Jensen Huang – boss of the leading chip firm, Nvidia – said in January he believed “very useful” quantum computing would come in 20 years.” In 20 years? I can happily report I will be dead by then. Yet the underlying setting is also true. If actual AI is depending on a quantum chip and fully explored shallow circuit technology, we can therefor presume that true AI is at least 20 years away. I believe that another setting is needed, but that is not here nor there at this point.
Don’t get me wrong. What we have now is great, even of a phenomenal nature, but it is not AI. Deeper Machine Learning is becoming more and more groundbreaking. And the setting together with LLM is amazing, it just isn’t AI. Together with the Microsoft setting of ‘in years’ comes nice. In an age that hype settings are required, the need for annual redefinition of something it isn’t will upset massive amount of sales cycles. They will suddenly need to rely on whatever PR is running with marketing setting the tome of what becomes next. A new setting for sales I reckon.
I have some questions on the quote “Microsoft says this timetable can now be sped up because of the “transformative” progress it has made in developing the new chip involving a “topological conductor”, based on a new material it has produced.” My question comes from the presumption that this is untested and unverified. I am not debating that this is possible, but if it was the quote would include (along the lines of) “the data we have now confirms the forward strides we are making” as such the statement is to some degree ‘wishful thinking’ it isn’t set in verifiable rule yet. It seems that Travis Humble agrees with me as we also get “Travis Humble, director of the Quantum Science Center of Oak Ridge National Laboratory in the US, said he agreed Microsoft would now be able to deliver prototypes faster – but warned there remained work to do.” But the underground on this is set to a timeline that gives doubt to the set of Stargate and its $500 billion investment. Consider that the investment is coming over the next 4 years, all whilst ‘interesting’ quantum technology is 20 years away. So what will they do? Invest it again? Seems like a waste of 500 billion. In that case can I have 15 million of that pie? I need my pension investment in Toronto (apartment included). The larger setting of wasteful investment. Does Elon Musk know that there is 500 billion in funds being nearly wasted?
And the simplest setting (for me) is also overlooked. It is seen in the quote “meaningful, industrial-scale problems in years, not decades”, that implies that there is no real AI at present. And my ego personally sees this as “Game, set and match for Lawrence”, as such all these sales dodo’s with their “You do not know what you are talking about” will suddenly avoid gazes and avoid me whilst they plan their next snappy come back. In the meantime I will leisurely relax whilst I contemplate this victory. It is the second step in my blog, the timeline shows what I wrote and when I wrote it. It could have gone the other way, but my degrees on the technology matter were clearly on my side.
And “Microsoft is approaching the problem differently to most of its rivals.”? Well, that is the benefit of taking another step, optionally innovative step in any technology. Microsoft cannot be wrong all the time and here they seemingly have a winner and that’s fair, they optionally get to win this time.
In the setting of ego I start the day (at 04:30) decently happy. Time I had a good day too. As such there is nothing to do but to wait another 240 minutes to have breakfast. Better have a walk before then. Have a good or even better, a great day today.