I just got hit with an idea (as ideas go). You see, I am from the world of Business Intelligence and Market Research and and idea just hit me. The setting is that data tends to be ‘humanized’, but what if it wasn’t? That is the central setting because the European GDPR has laws in place and I just thought of a way ‘around’ it. So take a setting where any MR firm requires data, but they cannot get that data because of the GDPR ‘complications’, so what is the actual issue? That doesn’t matter because Amazon, Google, IBM, Oracle and Snowflake have a way around that (Well a few more, but they do not matter). So take the next image
We have three top line population and it could be set to anyone (in that area) and as we set that population they are created a nearly unique number and never repetitive and that population gets exported, the numbers are. The MR people on the right get that number they populate the questionnaire(s) and it is send pack to the people on the left. Then that group sends out the questionnaires, the data is collected and send back to the group on the right. I reckon that this would be a nice challenge for Amazon and Snowflake I reckon. This might become an entire business unit and with privacy laws as they are placed in Europe, there might be a larger interest to seek such services. No hidden settings and all at the customers need and the consumers willingness to comply. I reckon that this might work, because as I see it, these Market Research people will see a dwindling of panel populations rather quickly in the next few years and then? Well, it would be up to them to think of a new setting, in the meantime I came up with this idea. And feel free to shoot it down straight off the bat and that is fine. As I said, it was just an idea grabbing me and as I was contemplating other venues. For that matter, how many interested parties would that bring in the Middle East and the Far East?
Good business is all where you find it and I think I found a population and an optionally interested partner. The question now becomes can these so called ‘Agentic AI Pushers’ see the setting that is offered to them and can it pass the General Data Protection Regulation requirements? If so, we are in business. Just another idea from yours truly. Time to create another gaming IP I reckon, time to flex that grey matter under my skullcap.
That is the setting and it remains to be seen as to where the crush will end up being. This morning I was surprised by a story in CDOTrends (at https://www.cdotrends.com/story/4729/how-agentic-analytics-replacing-bi-we-know-it) where Artyom Keydunov gives us ‘How Agentic Analytics Is Replacing BI as We Know It’ this is his view and as the co-founder and CEO of cube he is talking in his own street and that is his right. The issue with the article that it is really good, but there are some issues (from my point of view). The start is (optionally) great and with “For over two decades, the business intelligence (BI) dashboard has been the primary interface between data teams and decision-makers. These visualizations, charts, and KPIs have been invaluable tools for understanding what is happening inside a business. But in 2025, the dashboard model is showing its age. In a world where data moves at the speed of cloud transactions, connected devices, and global markets, static dashboards can no longer keep up. By the time a decision-maker logs in, refreshes a dashboard, and sifts through its filters, the critical moment for action may have already passed. Business leaders want answers, not just visualizations, and they want those answers as events unfold. A new approach, driven by AI and automation, is emerging to fill this gap.” There is merely spoken truth here and he is correct, but the Dashboard was ‘thought’ of by a Business Intelligence analyst and that tends to have hidden settings as that tends to be the case and the more it is set to the BI industry it was designed for, the better that tool tends to be. So when we see “By the time a decision-maker logs in, refreshes a dashboard, and sifts through its filters, the critical moment for action may have already passed” is not incorrect, but there is a time gap, we get that and the better the tool, the smaller the gap and as the designing analyst is better the more precise the tool becomes regardless of gap. So now we get to the ‘Agentic Analytics’ of the matter. It is programmed and based on the data it is trained on. Now, if this is all in-house data, that tends to be OK, but there is still the programmer and that is the culprit of the story. You see a programer is as good as the explainer hands him his data (tends to be a sales person) and that is already the issue. Sales persons are set to the blinkers then have (like pupils shaped as dollar signs) not the most eloquent setting to begin with.
So then we get to “The static nature of dashboards has made them a bottleneck in modern analytics. They rely on the user to know what question to ask, when to ask it, and how to interpret the results. When organizations scale, the proliferation of dashboards often leads to confusion rather than clarity. A company may have hundreds of dashboards, each presenting a slightly different view of the truth, leaving teams overwhelmed and second-guessing their decisions.” This is a truth and a half no matter how you tweak it. And the stage of “proliferation of dashboards often leads to confusion rather than clarity” is set to the organiser behind this and that tends to be a salesperson, CEO or CFO, as such money is the operative word and Agentic Analytics (AA) is set to data and clarity of collected data and upgrading this won’t make the data more clear, it merely showed how the dashboard fell short of what’s needed. So when we get to the ‘good’ part with “A company may have hundreds of dashboards, each presenting a slightly different view of the truth, leaving teams overwhelmed and second-guessing their decisions” we see the gap in the entire AA setting. It isn’t less confusing, the tweaked set of data is likely misrepresenting what was needed in the first place and I will grant you that this is my view on the data. I have seen dozens of cases where that was the case and in some cases it was with people managing data the size of a Fortune 500 company. So as we get to the really good part, Artyom Keydunov tells us “The promise of agentic analytics depends on trust. Without robust data governance, AI-powered systems risk surfacing misleading or inconsistent insights — and worse, they might automate actions based on flawed assumptions.” This is a powerful statement, it is not the trust part, this is inherently drawn from the loyalty a firm instills, it is “they might automate actions based on flawed assumptions” you see, ‘flawed assumptions’ is the key here and it is with many dashboards and as such with AA solutions as well. That just gave me an idea (perhaps cube has this) there is a between setting where the app could have documentation in the ‘second tier’ a setting where a document cog could be embedded in the software solution that is merely accessible at the core company that made this setting. So where some see “growth margin per quarter” the hidden blockchain will refer to that setting and the documentation will set the parameters for inspection. It could be any kind of blockchain with the setting of corporation – application – sequential counter and that is documented. You see, it is not what is now that matter, but in 5 years the reality of any solution (or AA) will require revision and wouldn’t it be great that you are able to vet what was (correct or not). So, now go back to any dashboard that was designed over 10 years ago and still in use. How many will not be able to tell you what was?
A simple setting merely shown to you and perhaps in your own firm there are several others. So make of this what you want. The article is quite good and even as it is talking in the street of Cube, it shows some common grounds we all need to have before we all go the way of the Dodo because AI told us to do just that and we end up at the edge of a cliff like darling little lemmings and when we realise we are at a cliff, the lemming behind us its pushing us in the back making us fall over. Nice ride, don’t you agree?
So have a great day and for me a new coffeeshop open tomorrow, so another option to try pointing myself for the simple reason that only the once trusted coffeemaker knew how we wanted our coffee, just like the users of a dashboard now relying on some AA that we are supposed to do it their way (which might not be wrong).
That is likely the setting we see today. I used the word ‘likely’ with some reservation as the implied parties are all kissing up to what they call ‘the ring of the orange entity’ and I am kind in the usage of the world entity (the other words were way to crass). Yet (at https://www.arabnews.com/node/2616094/business-economy) we see ‘Tencent Cloud accelerates Saudi expansion with new data region, AI services’ a setting that should be scorched in your minds for the simple reason that others are ‘hyping’ their so called AI setting and they don’t like other news that is not in their favor. We are given “Chinese technology giant Tencent is accelerating its cloud and AI push into Saudi Arabia, positioning the Kingdom as its primary hub for the Middle East under Vision 2030. On the sidelines of the Tencent Global Digital Ecosystem Summit 2025 in Shenzhen, senior executives told Arab News that the company is finalizing the launch of its first Middle East cloud region in Riyadh, part of a $150 million investment announced earlier this year.” Where they are addressing the second pillar of my three pillar solution and it is happening in Saudi Arabia. It is not merely that setting, they have bigger plans and these plans are seemingly underway. You see, in part we are given that side (at https://www.app.com.pk/photos-section/federal-minister-shaza-fatima-khawajas-meeting-with-saudi-telecom-company-stc-officials/#google_vignette) where we see ‘Federal Minister Shaza Fatima Khawaja’s meeting with Saudi Telecom Company (STC) officials’ There we see
and we get the gist of that meeting. Saudi Arabia is setting the borders way outside their national parameters and it makes sense as it gives them access to 251 million people, over 7 times the Saudi population. As I see it they now merely need Egypt (other efforts are already underway there) and Indonesia to make it a grand slam. And that gives them an almost certain setting to get 100 million subscribers to the Saudi Telecom Company (STC) group with expansion into Middle East and Asia. That is why Huawei and Tencent are playing it close to the vest as the expression goes. There is a chance they call it playing it close to the Kandura, or perhaps close to the Bisht. And as I see it, Saudi Arabia is only one step to dwarf the other 5G and telecom systems and that is where the Tencent Data centers come in. And as I see it, Tencent merely needs to connect two more places. Abu Dhabi and Riyadh and connect them to Hong Kong, Singapore, Seoul, Tokyo, Bangkok, Silicon Valley, Virginia, Frankfurt, São Paulo, Jakarta and they will become the biggest connected data centre on the planet. So, don’t believe the sludge that Microsoft is trying to sell you, as I see it, they no longer matter as per 01-Jan-2027. Oracle will connect to it all, as will Snowflake, AWS and whatever Europe has to offer, but as I see it, the Dutch relied on Microsoft, so that will be valued as laughter for money. And when that setting is set via a Chinese wall to whatever runs in China, America losses yet another battle that they set of presented bragging and other fiascos. And that writing was already done as I wrote ‘Evolutions towards the third cog’ on February 2nd 2024 (at https://lawlordtobe.com/2024/02/02/evolutions-towards-the-third-cog/) and at that point I truly believed that the UAE was picking up that option, but as it seems Saudi Arabia was a little more hungry for that revenue and now it seems that they might get it all. So the original latin expression “when two dogs fight for a bone, the third runs away with it” seems to apply here. And as CNBC gave us almost two weeks ago ‘OpenAI’s first data center in $500 billion Stargate project is open in Texas, with sites coming in New Mexico and Ohio’ where we see “OpenAI and Oracle are betting big on America’s AI future, bringing online the flagship site of the $500 billion Stargate program, a sweeping infrastructure push to secure the compute needed to power the future of artificial intelligence.
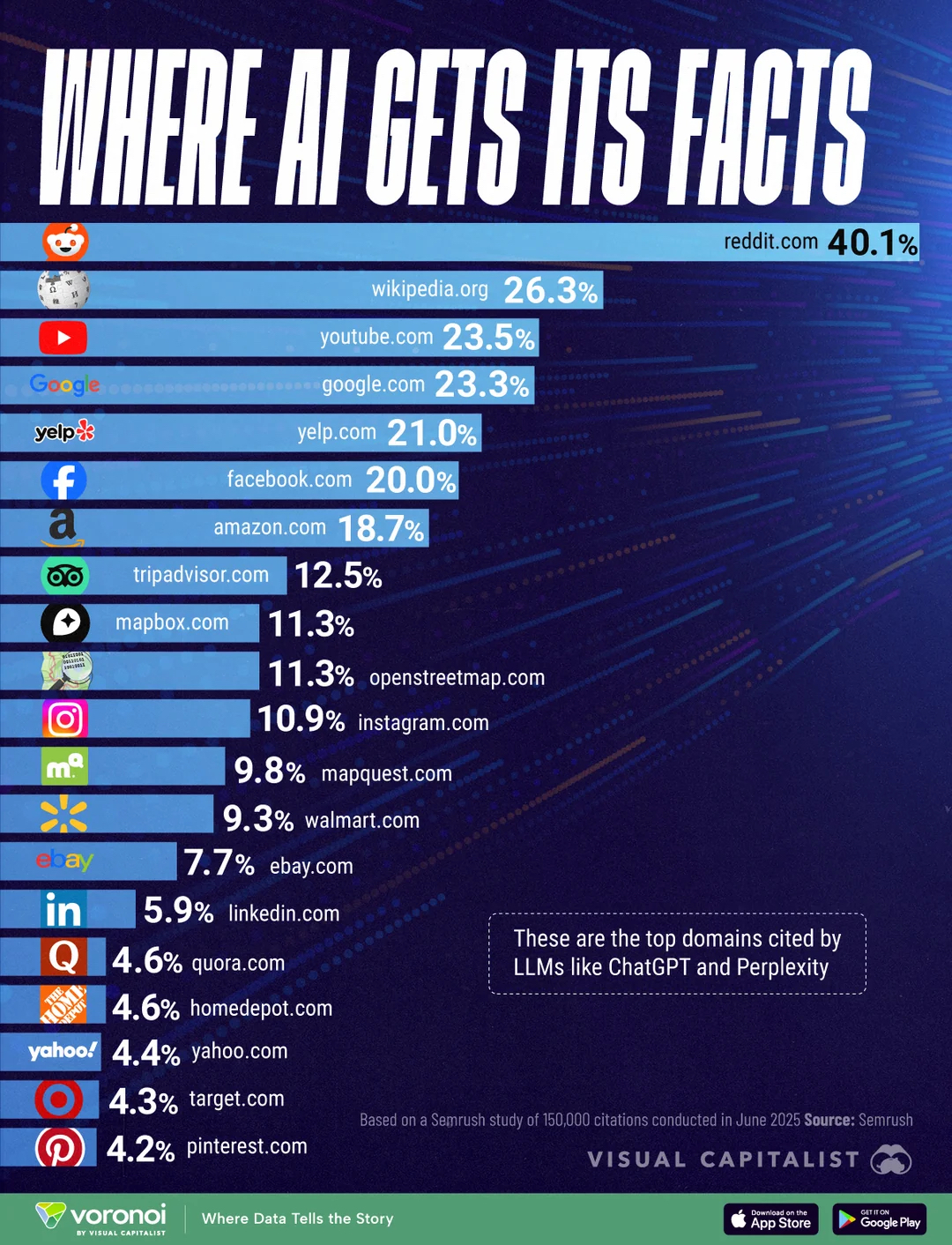
The debut site in Abilene, Texas, about 180 miles west of Dallas, is up and running, filled with Oracle Cloud infrastructure and racks of Nvidia chips. The data center, which is being leased by Oracle, is one of the most notable physical landmarks to emerge from an unprecedented boom in demand for infrastructure to power AI. Over $2 trillion in AI infrastructure has been planned around the world, according to an HSBC estimate this week.” We might need to adjust out views. It is true that OpenAI and Oracle are betting big, but they are set to the finders who are relying on a global impact and as I see it, when Tencent is connecting its data centers, over 20% of the planet will be somewhere else. So, do you think that the American people (340 million) will feed that massive engine? Consider that Europe is already fighting over where they want to be, those 450 million souls will not all traverse that setting and China with the expected 1.4 billion and the Saudi setting of over a billion (1.8 billion at present) gets Tencent the 3.2 billion, almost half the planet and that is merely the setting of Tencent and the STC. So how do you see that $500 billion go when you realise that some ‘proclaim’ that the AI facts come for over 40% from reddit (presumed speculation).
I reckon that someone will reinvestigate the ‘verification’ process in deeper detail (something I have been saying for over a year) and as such as the data is useless, so is whatever AI is sprung from that. The old Garbage in, Garbage out setting which some might have learned in the 80’s.
So whilst some might see that Stargate LLC is going to crash at some point, I would consider never ever investing in MGX Fund Management Limited which is owned by the UAE and I reckon (speculatively) that their $100,000,000,000 is going to go the way of the Dodo pretty quick. Of course if they have invested in Oracle, they will get the technology out of it and that can be redeployed in other ways, so that investment isn’t lost. But you need to know the contracts to define that step (I have no idea what the contracts stipulate). So is this certain? No, it is not. A lot of it is presumption and that is bigger than speculation, but it remains a guess. The larger part is that the STC, Saudi Arabia and Tencent are on course to make a nice killing (as the investment jargon goes). A setting that was set to productivity and gains through achievement. As I see it these two parties STC (Kingdom of Saudi Arabia and Tencent (Chinese government) are basically on track to become the larger players in this setting ever seen.
Have a great day and remember, you don’t need AI to order a coffee from the nice barista in your coffee corner.
Yes, I promised you a story full of intrigue, filled with bad Jedi and happy Sith only 20 hours ago. And here it comes (I’m watching Star Wars episode 2 at the moment). You see, there is a setting where we can watch the unfolding of what some laughingly call ‘Artificial Intelligence’ (it would be if it was designed by the CIA, but the American Administration is now in shutdown). To get there there are three parts.
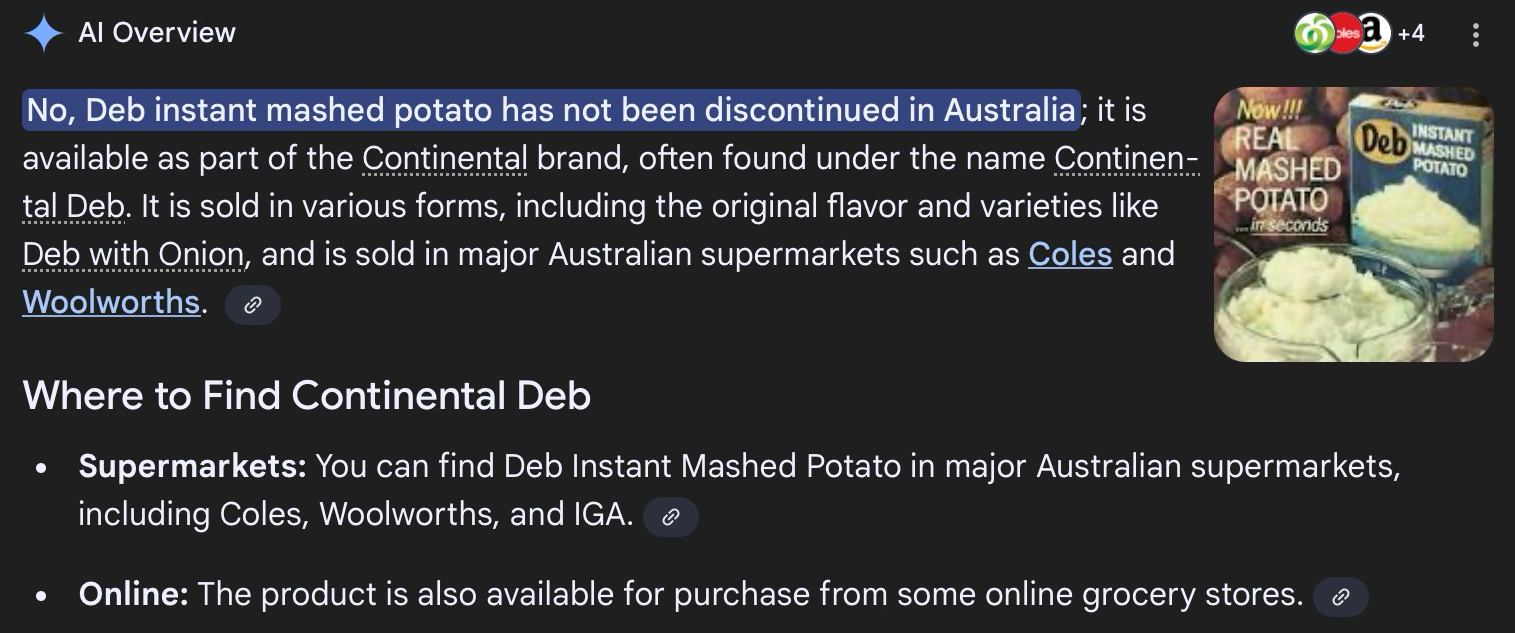
In part 1 we look at the ‘disinformation’ and here we see the parts that do not match. You see, Dab Mashed potatoes with unions were discontinued in both Coles and Woolworths. The IGA still has it as I was able to verify in person (I had to travel to Summer Hill for that). So this is part 1.
Now we get to the slightly better stuff. You see, some might think that combining DML with Predictive Analytics (some think it is AI) is a solution. You merely set this in a massive database and voila (a theatrical of ‘here it is’) and that was that. This is merely my version of what I think it is happening.
You merely set the model on all the articles you have and you take settings of ‘minimum order size’ ‘estimated margin per item’ and a few other things and there you have a matrix showing the items that just don’t make the cut for your ‘predicted margin of profit’ model and they are ‘discontinued’. And it goes on for nearly all retail models, and it might be a consideration that this is a speculated idea of why PM Albanese invited Lulu into the mix against Coles, Woolworths, IGA and Aldi. I have no data on this, but I reckon it might be a reason that it stops the DML/Predictive Analytics madness. You see, there is a setting that it is folly to get any customer 100% happy (it really is), so these giants are heading for a mere 90% and they throw out the least margin articles out of their consideration, but there is a flaw, thrown out 10 articles is a start, but that leaves one less at 90% and 9 less at 1%, as such you have a base of 81%, so now we are off to the races. And as there is no substitute for added pressures, Lulu gets invited to Australia (in case the others went the way of the dodo, I meant Coles and Woolworths). There is no supporting evidence, so this is (highly) speculative. But there is another setting. You see, this solution requires programming skills and that is where ‘Accenture plans to boot staff it can’t train to use AI, 12,000 already culled’ comes in. This solution will require hundreds, if not thousands of people being reskilled and places like Accenture cannot do that, unless they trim the staff they have in several places. And 12,000 were ‘culled’ because it hinders their bottom line. To support this I give the following thoughts ‘What time was taken to assess a person whether he/she could be re-skilled?’ Who had the knowledge to assess this and what time frame was developed here? If this goes through it will mean a lot of engineers will be required in a short term setting.
And I merely used the Deb potato mash as an example, but what happens when it this pattern is released on pharmacy or other items? So whilst we might think that Accenture is dabbling in greed, the plain setting is that this is the direction that commerce is driving itself into.
And this setting is about to be set on unverified data. Consider that Gemini AI had it wrong on Coles and Woolworths (see image), so what else did they get wrong and when that data is unverified how will the Predictive Analytics work with any level of accuracy? Mere simple questions at the top of my mind. And that was the setting of that ‘so called’ AI.
Now, the setting is that parts of this are speculation, but does this make it wrong? It might be unverified, but the setting of the 12,000 culled into joblessness is recorded all over the media, and it is for the reason of ‘reskilling’ but what makes it impossible to reskill a person? As I see it, it is merely time and that is as I see it, time Accenture seemingly doesn’t have. And the setting of DML and Predictive Analytics? I see that as a limit towards viable data and that is the setting that plenty are ignoring. Some will ‘embrace’ the customer telling them that their data is awesome, but that is the second folly in this. Most of them are merely at the tally stage and their systems tend to come from legacy data, implying it is filled with holes and holes of non-data.
So think of this what you want, but the larger setting is about limiting YOUR ability to choose because it affects THEIR profit margins. Come to think of it, when was the last time you saw Sarsaparilla on the shelves of your supermarket? I remember a few years back there was Black knight licorice, where did that go? So think of all the things you liked and it is no longer there, why is that? Some are unviable as they cater to hundred of thousands of customers and they need to ‘adjust’ their stock accordingly. But what was denied to you? And the setting of adding predictive analytics to their profit mix is only making that worse for you. So what about part 3? Well that is where you the consumer comes in, it is what defines you, not what ‘their’ unverified data says you are.
So have a think about what you are about to lose and have a great day and enjoy your next coffee, if only to force you to their brand of Nescafe.
That is always merely a breath away. At some point the decline of Oracle became a setting and the looting of the place by the Byzantine Constantine the Great contributed to the Demise of this place. But for the most part I have never heard that Oracle became a non issue. It always struck me weird that this never happened. Even today most of us call the givings of the gods ludicrous, or perhaps better as the Catholics might say sacrilege. Yet the power of the Oracle of Delphi has seemingly never waned to zero.
This is the thought I had today as yesterday the news of Oracle was pushed to the core (mostly at Yahoo Finance) with all kinds of messages. We start with ‘Oracle (ORCL) Initiated at Sell by Rothschild Redburn, $175 Price Target Set’ and it is followed by “According to the firm, the market is materially overestimating the value of Oracle’s contracted cloud revenues. In big, single-tenant, large-scale deployments, the company acts more like a financier than a cloud provider, “with economics far removed from the model investors prize.”” As well as “Oracle’s five-year cloud revenue guidance is equal to $60B in value. This reflects that the market is already pricing in a “risky blue-sky scenario that is unlikely to materialize.”” My first issue is “Why?” You see, even as I do not trust (or believe) AI, its foundations is set on data as it always was set. Data is the holy grail of AI that much is certain and it will proceed to be for decades to come. So, who will you trust with your data? Microsoft with its Azure? As I see it Microsoft can’t see real innovation through the brushes of their own proclaimed innovation and as hackers proclaim that Israel is storing a particular form of its ‘defense’ data in Azure, there might be a security issue as well and that is a total blocker. There are good data solutions in Google, IBM and Amazon, but they all consider Oracle to be the Rolls Royce of data carriers. Then we get the next setting of ‘Nvidia And Oracle Headline 7 Promising Stocks With Mojo: Analysts’ and as they give us “What’s especially impressive is that these stocks are already up 30% or more this year. That blows away the 12.9% gain by the S&P 500 this year. So these are the big winners Wall Street still has high hopes for.” As such we see that in spite of all the stupidities the American political engine performs these two are kind of hot and it makes sense that they are, even if I have some reservations, there was never a doubt that Oracle could grow through it. Making the Statement from Rothschild debatable and me without economic degrees calling Rothschild on this is better then sex (even if Olivia Wilde would call on me in the next hour calling me a fucking tool, this is followed by a rather loud giggle by me). So when we get to ‘Why Oracle’s Cloud Computing Deals With Meta Platforms and OpenAI Make The “Ten Titans” Growth Stock a Top Buy Now’ A setting that the Motley Crew gives us (what do they know of IT?). We are given “the company announced plans to increase Oracle Cloud Infrastructure (OCI) revenue by more than 14-fold in five years. But that news proved to be just one splash amid a sea of waves. Reports indicate that Oracle and Meta Platforms are in talks on a $20 billion cloud computing deal. And Oracle and OpenAI are building on their $300 billion partnership with the rollout of five new data centers custom-built for artificial intelligence (AI).” No matter where they are, a setting of a 1400% revenue growth in 5 years is massive, unbelievable massive. Now, no matter how this turns, the one day lightbulb who believe in their AI settings will have to invest the money to make it work and that is the beginning of a setting where Oracle wins, no matter how that turns out. As such the AI wannabe’s are fueling the increase and funding the foundations of these data centers. And we are given “Google Cloud serve a variety of general compute customers. However, Oracle’s data centers are specifically designed for AI.
Oracle is a good example of why lacking a first-mover advantage isn’t a deal-breaker. Oracle’s data centers are newer and faster. And it’s bringing over 70 of them online in just a few years, which is why it expects OCI growth to reach an inflection point in fiscal 2027.” I reckon that it will serve several purposes, but it is more AI set than other centers. Although I have no real idea where Amazon and IBM stand. I reckon that Oracle could cater to the needs of Snowflake and allow its customers to grow their needs and it will do so a lot better than being a little IT guy Azure blue with questions. I saw the need for applications in the lost and found section that could grow adaptation by nearly all airports and when you are in, you are in. I reckon that Interworks should talk to adaptation Snowflake through Oracle, but that is just me.
Then we get an article that matters (at least it seems to). We are given ‘Analyst Says Oracle (ORCL) Deal With OpenAI is ‘Very Risky’ – ‘Not a Customer That Can Pay Their Obligations’’ and I see “One is if you go back to the transcripts from Oracle Corp (NYSE:ORCL) for the last few quarters, you’ll see that it’s not just the last deal from OpenAI that increased their backlog. It’s actually been several quarters where it’s really OpenAI that’s been driving all of this. Having that is the only thing that’s added value to Oracle Corp (NYSE:ORCL) is very risky. That’s not a customer that can pay all their obligations. They’re double, triple booking, maybe quadruple booking capacity. They will not be able to live to those obligations. So if you’re adding $400 billion of market cap to Oracle Corp (NYSE:ORCL) based on that, I think we should revisit the math.” OK, I am in (not knowing the math he talks about), and we see “OpenAI is expected to burn about $115 billion over the next four years and is not projected to be profitable until 2030. Even after Nvidia’s latest $100 billion investment by Nvidia, OpenAI will likely need to raise over $200 billion in total funding to cover its commitments. Some analysts believe Oracle may need to borrow tens of billions to build enough data centers for the deal.” OK, that sounds fair, but some seem to forget that Larry Ellison is worth 344,000 million (sounds much better then 344 billion) as such he can get those numbers without any question. And if he is right he will triple his value overnight as these data centers come online. And that is when the article shoots itself in the foot. They do it by giving us “While we acknowledge the potential of ORCL as an investment, our conviction lies in the belief that some AI stocks hold greater promise for delivering higher returns and have limited downside risk. If you are looking for an extremely cheap AI stock that is also a major beneficiary of Trump tariffs and onshoring, see our free report on the best short-term AI stock.” You see, no matter how great the idea is, it will still need data and Oracle is the best. They can side with fast talking sales people at Azure and see their projects fumble and watch delay after delay happen. As those promising returns fall to ash you can contemplate your choices. That being said, any AI idea is temporary at best, as such the investment in an Oracle engine seems a much better setting and these people have been in data for decades. As such I see the value and the foundation of Oracle, even if some do not or question the setting of Oracle.
I wonder how Pythia sees my predictions and even as I am called ‘duly’ to serve Apollo (I serve Lord Hades in all things) the foundation of predictions is seemingly driven by personal insights and I have been at the foundations of data going back to 1982 so I do feel I am on the right track.
Have a great day and don’t forget to chew your laurel leaves, whether you are about to enjoy a coffee or not. Oh, get your coffee quick, the US government shuts down in 7.5 hours.
That is the setting I am having in 1 o’clock in the morning. The news (and the internet) is currently overloading with Jimmy Kimmel stories as well as vindictive settings against Disney and I get it. When the media who is trumpeting free speech is becoming the bitch of President Trump, people will not take kindly to this. Apparently the subscription servers at Disney went down as it was overloaded with cancellations (according to some sources). So I had to look all over the place on the settings of finding something to write about and Tom’s Hardware was one source who supplied the goods. The story (at https://www.tomshardware.com/tech-industry/artificial-intelligence/microsoft-announces-worlds-most-powerful-ai-data-center-315-acre-site-to-house-hundreds-of-thousands-of-nvidia-gpus-and-enough-fiber-to-circle-the-earth-4-5-times) gives us ‘Microsoft announces ‘world’s most powerful’ AI data center — 315-acre site to house ‘hundreds of thousands’ of Nvidia GPUs and enough fiber to circle the Earth 4.5 times’ and even as I don’t care too much about what happens in Wisconsin (other than the need to protect cheeses, I really like cheese) is the fact that when I see an article with that much data, I start looking for missing data, I am wired that way and it is less than 4.5 times around the planet.
But we got something, the setting is given with “This is likely a comparison to xAI’s Colossus, which uses over 200,000 GPUs and 300 megawatts of power. Microsoft didn’t specify its exact number of GPUs nor the expected power consumption.” And that is the ball game. You see, the setting of 300MW is not just a lot, it is the entire ballgame. Now, there is evidently enough power in Wisconsin, but is it enough? Consider a simple PC. It has a 600W power supply. Now this is not the same, but I am getting to that. Take 200 PC’s, that makes it 120,000 Watts of energy. Now consider that hundreds of PC’s are needed to even partially validate the data coming into that place. You need data verification spots to do that. The larger setting could be done by data entry people, people who go over the received data and they need to work quick, almost uninterrupted. As such the quote “Microsoft didn’t specify its exact number of GPUs nor the expected power consumption” is as I personally see it, massively deceptive. Just like the stage of Builder.ai where Microsoft set it to over a billion dollars and in months that money was gone, they apparently spend it on under 200 programmers (test engineers) and that is merely the start of it. And when we talk about enough fibre to circumvent the planet 4.5 times you get 57,402 km of fibre won’t that take any energy? The numbers aren’t adding up and even as Wisconsin has energy, there is every likelihood that they ‘suddenly’ have a shortage of energy. Oh, what a damn shame and the setting of any data centre is that in case of a shortage of energy it all ends right quick, the moment the surplus hits zero, the issues start and they will immediately escalate.
Further down that page we see the mention of Elon Musk: “Elon Musk confirms xAI is buying an overseas power plant and shipping the whole thing to the U.S. to power its new data center — 1 million AI GPUs and up to 2 Gigawatts of power under one roof, equivalent to powering 1.9 million homes”, well good luck with that idea. I am not saying it is impossible, but the setting of getting that all placed in a new location still requires a lot of concrete and not to mention the stage of the resources to get the plant going, so what is it? Gas, oil, coal, Uranium?
So what is fueling the Microsoft plant? And how much surplus energy will Wisconsin have left at that point? As I see it, there is a reason that Microsoft doesn’t give out the expected power consumption. And there are a few more items on that list, like validators (could be done remotely) so hundreds of people calling into that centre what drives the telecom settings? All issues that would have to be tackled on day one.
As I see it, there is a lack of focal points, but as I see it, those who spin aren’t interested in that concept at all. Merely the floatation of the name in conjunction with “‘world’s most powerful’ AI data center”, didn’t Microsoft do this once before? Oh yes, the most powerful console in the world. How did that end with that Xbox series X? As far as I know it is trailing the weakest console (Nintendo Switch) by a lot and it is also trailing the PlayStation 5 a fair bit. So I am not keeping my hope up when Microsoft is juggling the setting “World’s most powerful…anything”
But then I have seen them play these cards for almost 40 years. And they could have taken advice from IBM on certain matters, like “This page is intentionally kept blank”
But that is just me.
The second setting is being pushed forward. I don’t want to write the wring thing and there are a few missing cogs in that story. Like the ‘new’ location on $4,300 billion retirement funds. And no one is talking so I have to dig.
Well, have a great day, time for Sunday to get a sun (in 4 hours) and consider looking around for freedom of speech, Disney seemingly can’t find it.
Yes, I have said that on several occasions, there is no AI and whatever there is has verification issues. Today I illustrate this YET again and here in this case Google is as much to blame as many others.
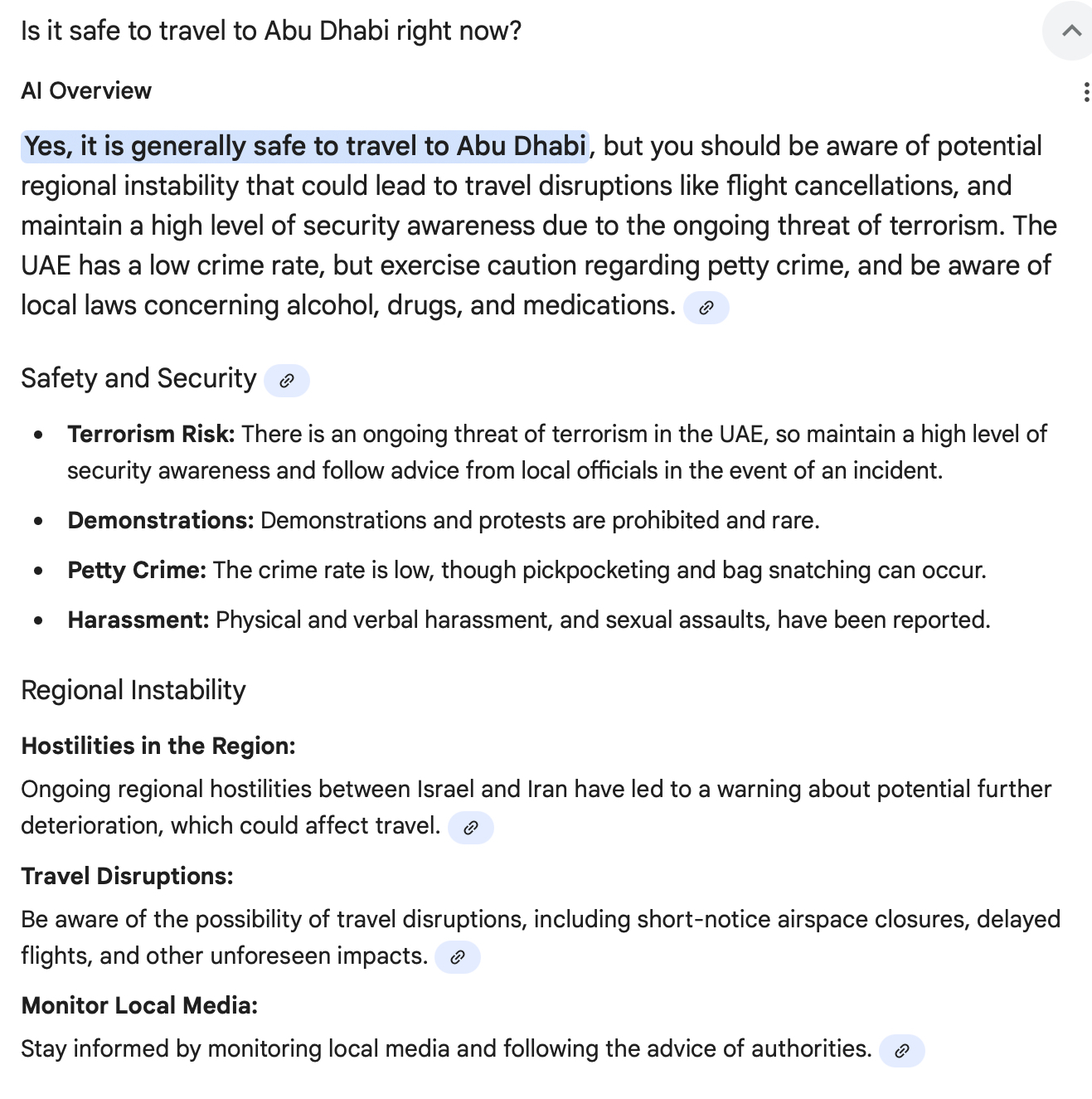
So we have two images, the first one gives us
That there are risks. I was taken a little back, The UAE is one of the safest places on the planet. So I decided to ask the same question a little different and I added the term “in 2025” so as we see the second setting
We see the initial feeling I had about the country. And there are an abundance of articles showing the safety of the UAE (and Abu Dhabi), as such I want to kindly wake Sergey Bring the fuck up and I am wondering whether he needs to address his Gemini settings a little. Perhaps American tourism decline settings is altering the verification settings?
As such there is one little situation, the setting that whatever bigtech calls AI cannot be trusted (which I already knew). The setting of verification that is up and about and that is the major handle in whatever that (AI) is. We need to realise that there is no AI. There is DML (Deeper Machine Learning) and there is LLM (Large Language Models) and they are awesome, but they are depending on the programmers you throw at them and it is not foolproof, there are issues (as you can see).
This is not a large article. I have said it before and now within 5 minutes I had the setting I needed. I reckon that all of you want to make a separate ‘judgment’ on whatever these people call AI and whether it might show your local environment in a limelight you could check. And just for fun (I tend to be a whacky person) I am adding the ‘American Tourism decline’ here too.
Just to set the premise, consider that this was given 4 weeks ago: “In June, Canadian residents returned from 2.1 million trips to the United States, representing a 28.7% decrease from the same month in 2024 and accounting for 70.8% of all trips abroad taken by Canadian residents in June 2025.” And the story here becomes verification. You see, who (or what) is feeding the AI models? When the data cannot be verified, how is the data conceived? Because this data is fed, by whom becomes the story and the media (as a whole) becomes less and less reliable.
Have a great day, almost time for me to take a walk towards my brekky.
That happens at times and I reckon that at some point I will have to give in to that setting as well. It started this morning when I was advised that I might have cancer, it might be benign, the biopsy will be done over the next week, then they know what they have. I was unusually cool about it all. As such as a friend of mine was ‘culled’ by the big C (a curry billboard shattered his skull), I can confirm that my weird sense of humor has not been devastatingly impacted at present.
So I have two ideas on my mind. The first one is that Peter Jackson (director Lord of the Rings) still owes me $17.50 He owes me that amount from 1992. But the other one is the one that matters to me. For that we need a small sidestep towards the article that Fortune gave us (at https://fortune.com/2025/08/18/mit-report-95-percent-generative-ai-pilots-at-companies-failing-cfo/) where we see ‘MIT report: 95% of generative AI pilots at companies are failing’, it is here where we see “Despite the rush to integrate powerful new models, about 5% of AI pilot programs achieve rapid revenue acceleration; the vast majority stall, delivering little to no measurable impact on P&L. The research—based on 150 interviews with leaders, a survey of 350 employees, and an analysis of 300 public AI deployments—paints a clear divide between success stories and stalled projects.” The report is two weeks old, but today I had a reason to tag it, it affects my future and as I see it, it impacts it in a positive way. As such the second quote doesn’t quite get us there, but there is an offset. It is seen in “for 95% of companies in the dataset, generative AI implementation is falling short. “The 95% failure rate for enterprise AI solutions represents the clearest manifestation of the GenAI Divide,” the report states. The core issue? Not the quality of the AI models, but the “learning gap” for both tools and organizations. While executives often blame regulation or model performance, MIT’s research points to flawed enterprise integration. Generic tools like ChatGPT excel for individuals because of their flexibility, but they stall in enterprise use since they don’t learn from or adapt to workflows, Challapally explained.” The part missing is data and verification. WE can look for other articles where we see the failures of AI. But the largest setting is never discussed. What we call AI isn’t it, they mess around with “GenAI”, they package it like it is a new version of “generative AI” but in the end it is merely DML with optional LLM in place. It is as I call it “Near Intelligent Parsing” parsing because it is existing data, it cannot leap on non existing data and the setting we see are basically a little more than predictive analytics. It is a next step.
So why is this important? Well, for me there is a side that has worked in Technical support and customer care for nearly two decades. And as I see it, the quality people who need to act will see it. As such I think that Lawrence Ellison (Oracle) can see the light he is currently coping with. Large customers will need their technical support, their customer care and here I am ‘sneakily’ asking him for 10 million (post taxation) out of his two hundred fifty thousand million (aka $250 Billion) stockpile. Seems like the smallest of amounts. Oh, and I pride myself on being a return on investment I have proclaimed for the length of my working career going all the way back to 1982. That is 43 years of experience (twenty in technical support) and I have none in Oracle. But I know that support settings that any companies have. And Oracle will need these people soon enough. Wherever he wants to send me, it is almost fine by me. As I see it no one wants to work in Russia and America is a big no no (its a Trump card). But the UAE (ADNOC) and Saudi Arabia (ARAMCO) do make the list. And Oracle needs these large companies and especially support staff in these locations. Personally the UAE wins, but it is what Oracle needs and I am willing to move to Canberra at the earliest settings. We seen to be at an influx where the governments and large corporations need manpower. Microsoft and Amazon need to learn this and whilst they falter, Microsoft is shedding 9000 people and investing in AI, but when you consider that 95% falters, you can imagine when these systems fall short, all whilst at that same time, Windows seemingly lost 400 million users in the past three years. Do you think this is coincidence? Yes they can clean some up with NIP, but they will fill larger holes in that meantime and losing people in the process. Google and Amazon are on that same setting. But Oracle is too complex. As I see it, it needs staff in the near future and I am betting that they cannot afford to lose the manpower and I am willing to bet that as they take over clients from AWS and Azure (the latter especially) they will need more people and that’s where I come in. Not merely tech support staff, but as a trainer having made my brand of training people, I am willing to bet that Oracle might have a place for me (even a flake like me).
I have always stood my setting in this and after a long time I am proven correctly and the next generation is largely unable to deal with the support pressures and that works for me in places like ADNOC. So I believe that Oracle might be my solution towards a few settings that never worked for me. And there is something less like-able about forced to hand my IP to Microsoft whilst receiving a mere 0.001 on the dollar. I might given it away in other ways (to others) if Oracle shows to be my ‘knight on a white horse’ and there is something satisfying on that setting. I get to see Microsoft lose thrice over.
As such those with an affinity with technical support to consider the places they can flock to. I gave some of my IP to Elon Musk (Musk already owed the ideas anyway), and I keep on fueling gaming IP to other channels too (non Microsoft systems) and there the Amazon Luna has options too. Still the news from this morning (even as it doesn’t hit me hard) it made me see that I have to put my affairs in order and one of them is to deny Microsoft my IP.
And there is a second setting, as Google and Microsoft are shedding people, the larger companies need to scoop them up quickly, because internationally these people will be wanted rather quickly. For Americans there is Canada as a first, but do you think they will spread their wings to other nations? Time will tell, but as I see it 2025/2026 will be the year where we all consider the stage of the brain drain. And take that with faltering AI projects, the turn of of places suddenly being short on tech support will falter massively and as we know: “no support, no sales” a nice catch phrase, but their AI will tell them at some point (one might hope).
So have a great day and I will ponder what will become of me when the biopsy doesn’t show a benign setting.
Well, that is the setting we are given however, it is time to give them some relief. It isn’t just Microsoft, Google and all other peddlers handing over AI like it is a decent brand are involved. So the BBC article (at https://www.bbc.com/news/articles/c24zdel5j18o) giving us ‘Microsoft boss troubled by rise in reports of ‘AI psychosis’’ Is a little warped. First things first. What is Psychosis? Psychosis is a setting where we are given “Psychosis refers to a collection of symptoms that affect the mind, where there has been some loss of contact with reality. During an episode of psychosis, a person’s thoughts and perceptions are disrupted and they may have difficulty recognizing what is real and what is not.” Basically the settings most influencers like to live by. Many do this already for for the record. The media does this too.
As such people are losing grips with reality. So as we see the malleable setting that what we see is not real, we get the next setting. As people lived by the rule of “I’ll believe it when I see it” for decades, this is becomes a shifty setting. So whilst people want to ‘blame’ Microsoft for this, as I see it, the use of NIP (Near Intelligent Parsing) is getting a larger setting. Adobe, Google, Amazon. They are all equally guilty.
So as we wonder how far the media takes this?
I’ll say, this far.
But back to the article. The article also gives us “In a series of posts on X, he wrote that “seemingly conscious AI” – AI tools which give the appearance of being sentient – are keeping him “awake at night” and said they have societal impact even though the technology is not conscious in any human definition of the term.” I respond that giving any IT technology a level 8 question (user level) and it responds like it is casually true, it isn’t. It comes from my mindset that states if sarcasm bounces back, it becomes irony.
So whilst we see that setting in ““There’s zero evidence of AI consciousness today. But if people just perceive it as conscious, they will believe that perception as reality,” he wrote. Related to this is the rise of a new condition called “AI psychosis”: a non-clinical term describing incidents where people increasingly rely on AI chatbots such as ChatGPT, Claude and Grok and then become convinced that something imaginary has become real.” It is kinda true, but the most imaginative setting of the use of Grok tends to be
I reckon we are safe for a few more years. And whilst we pour over the essentials of TRUE AI, we tend to have at least two decades and even then only the really big players can offered it, as such there is a chance the first REAL AI will respond with “我們可以為您提供什麼協助?” As I see it, we are safe for the rest of my life.
So whilst we consider “Hugh, from Scotland, says he became convinced that he was about to become a multi-millionaire after turning to ChatGPT to help him prepare for what he felt was wrongful dismissal by a former employer.” Consider that law shops and most advocacies give initial free advice, they want to ascertain if it pays to go that way for them. So whilst we are given that it doesn’t pay, a real barrister will see that this is either lawless, trivial or too hard to prove. And he will give you that answer. And that is the reality of things. Considering that ChatGPT is any kind of solution makes you eligible for the Darwin award. It is harsh, but that is the setting we are now in. It is the reality of things that matter and that is not on any of these handlers of AI (as they call it). And I have written about AI several times, so it it didn’t stick, its on you.
Have a great day and don’t let the rain bother you, just fire whomever in media told you it was gonna rain and get a better result.
That is the setting I just ‘woke’ up from. A fair warning that this is all PURE speculation. There are no hidden traps, there is no revelation at the end. All this is speculation.
You see, some will recall the builder.ai setting and there we see “Builder.ai was a smartphone application development company which claimed to use AI to massively speed up app development. The company was based mostly in the United Kingdom and the United States, with smaller subsidiaries in Singapore and India.” At this time we are given “The real catalyst wasn’t technical failure — it was financial mismanagement. According to reports, Builder.ai was involved in a round-trip billing scheme with one of its partners. Essentially, they were allegedly booking fake revenue to make the business look healthier than it was.” And the fact that Microsoft was duped here makes it hilarious. But was it? You see, as I see it AI doesn’t exist (not yet at least) so this setting didn’t make sense, it still doesn’t. Apart from the fact that there were 700 engineers involved (which made the setting weird t say the least) and that was set in a larger space. But what if there was no ‘loss’ for Microsoft? What if builder did exactly hat was required of them? When I got that thought, another beeped up. What if this setting was a mere pilot? You see, there are data issues (all over the place) and Microsoft knows this. What if these 700 engineers were setting the larger premise. What if this is the premise that Sam Altman needs? What if the enablement the is caused between Sam Altman and Satya Nadella and their needs? What if that setting isn’t merely data, but programmers? What if OpenAI is capturing all the work created by programmers? You see, data can be collected, capturing the work of programmers is a little different and OpenAI gets at present “OpenAI is set to hit 700 million weekly active users for ChatGPT this week”, as far as I can tell 90% is simple rubbish, but that 10% are setting their fingerprints on the programming of the future. And whilst this is going on, the ChatGPT funnels are working overtime. As such these programers are pushing themselves out of a job (well not exactly) they still have jobs in several places, but the winners here is team Altman/Nadella. They are about to clean house and when the bulk of the programmers is captured, automated program settings are realised. It isn’t AI, but the people will treat it as much. And this setting is really brilliant. We all contributed to a new version of Near Intelligent Parsing. One that has the frontlines of the crowds, millions of them. And no-one is the wiser as such.
Perhaps some are and they do not care. They will have their own partitions on this all and the setting will regurgitate their logic and as such they will be the cash makers in the house. So, we are pricing ourselves out of a jobs, out of many jobs. But as I said, this is merely speculative and I have no evidence of any kind. Yet this was the setting I see coming.
Now, let see if I can dream lovely dreams involving a lovely lady, not an Grok imaginative lady of the night. You know what I mean, Twitter is filled with them at present.
Have a great day, it’s 5:00 in the morning in Vancouver, I’m almost seeing Monday morning, less than 2 hours to go.