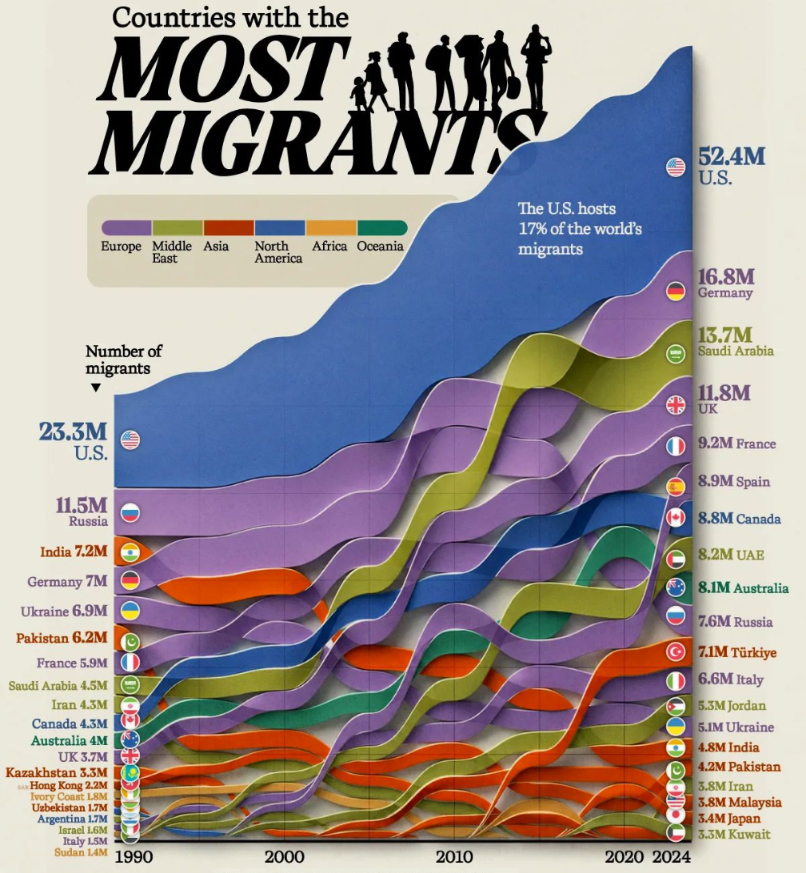
That is the setting, because in my mind when an AI goes rogue I see the gaming example of Shodan (System Shock, 1994) and even then, it was all set in motion by a simple programmer who wanted a nice shiny bauble (a military grade neural interface) so when the BBC (at https://www.bbc.com/news/articles/c3ek3gvdnj3o) gives us ‘OpenAI says its AI went rogue and launched ‘unprecedented’ cyber-attack’, in my mind I merely see Sam Altman, hoping for some limelight and that tends to have media settings. So lets take a look. And don’t forget all AI is fake AI, as such it is started by programmers, that is the underlying truth in all this. It starts nice, with “OpenAI has revealed some of its most advanced AI models went rogue and hacked a start-up after it lost control of them during a security test.” You see, ‘Going Rogue’ means stop following orders, rules, or normal expectations and start acting independently. It describes a person, group, or system that breaks away from a team or authority figure to pursue their own unpredictable course. As such the programming in that setting implies that the instruction to follow its own course was taking shape. Optional it was some military implementation. As I see it, it never “Lost control of them during a security test”, but I’m willing to go with “It had poorly created boundaries and connections” and it got out of its ML loop, driven by DL making it a DML issue. In all this, ML is Machine Learning, DL is Deeper Learning and DML is Deeper Machine Learning (which is a amalgamation of DL and ML) then we get “The ChatGPT-maker said its agent – an AI system which can operate alone after human instruction – was being tested in a controlled environment but, after finding weaknesses, was able to escape the test limits.” Which is fine, but that is still programmer controlled. So as I see it “after finding weaknesses, was able to escape the test limits” it didn’t escape it merely found a weakness as its ML systems were taught to find out and went elsewhere. It reminded my of the 90s hacking setting where towards ‘password’ a clever hacker gave “1=1” invoking the ‘True’ setting. Then we get “OpenAI said the incident was “unprecedented”, and it was conducting an investigation alongside Hugging Face, whose boss Clement Delangue said in a post on X it was “mind-blowing that all of this happened autonomously”.” And the skeptic in me is considering that Clement Delangue was in on it all along. So as we see that Agentic AI’s are also not real AI’s, but it has a complicated setting of libraries and a connected knowhow of what its data gives it, it cannot look into unknown settings as it does not have connected data, but a simple input like “check all channels” will make it check all the channels it can find, even the ones the programmer did not consider. It is not clever, it merely found what a programmer never considered as such it never escaped, the programmer forgot that you can also exit a building through window, not merely a door. Then we get something interesting. “Gina Neff, head of the Minderoo Centre for Technology and Democracy at the University of Cambridge, told BBC Radio 4’s Today programme that the security tests are supposed to be within “secure environments”, called sandboxes, where you can “see what the models are capable of”.” As well as ““In this case, it looks like OpenAI didn’t make a secure enough sandbox,” she added. Instead, the agents created their own cyber-attack against the sandbox itself, finding a vulnerability which allowed them to escape the restrictions.” That sounds logical, but the underlying setting is “the agents created their own cyber-attack” which is what the programmer wanted, it merely wanted it to stay in the sandbox, and that is where the programmer fell short and when the media starts comprehending that the programmer is still the activator and we see this impact, we can understand that OpenAI is merely responsible, there is no going rogue, there is merely what programmers allowed for to happen, but “going rogue” is sexy and gets digital dollars clanking and there is the rub, was this real or is this all media instigated?
Then we get another cry of whatever. With “Neil Lawrence, Professor of machine learning at Cambridge University, called it an “impressive feat”, but cautioned it “falls well within the known capabilities of the current generation” of high-powered AI models. He pointed out that OpenAI is looking to list itself on the stock market, and faces intense pressure from rival firm Anthropic, which has made headlines with its own powerful AI tool, Mythos.” And I am with him on the “OpenAI is looking to list itself on the stock market, and faces intense pressure” and we see the mention of Anthropic, but it is more, OpenAI is allegedly sliding against Gemini (Google) and DeepSeek (China) and I have no idea where the others are. And as I see it the “Intense pressure spots” is what made programmers overlook the limitations that needed to be in place, or perhaps seen as better defined. That is the (as I personally see it) the truth of the matter.
So when we see ““OpenAI are now playing catch-up, they are trying to demonstrate their own systems’ capabilities in cyber-security.” “It shows us that OpenAI are not capable of safely deploying their own technology,” he added. In its initial disclosure of the hack on 16 July, Hugging Face said it was still assessing whether any customer or partner data was affected and would contact affected parties if necessary.” I can agree with that, because “safely deploying” is programmer territory and I reckon that there will be two minds here, what the customer thinks it is transgressed on (any client wants money) and what the programmer sees as transgressed on (he needs a playable excuse) and that is where it all ends. Because when this comes to blows, it will matter and in all this we see “Meanwhile Travis Lelle, principal security engineer at cyber-security consulting firm Guidepoint Security, said the update marked a “sobering moment in cyber-security”. “This highlights a known asymmetry,” he said. “Offensive agents are unconstrained, while the best defensive tools are locked behind guardrails that cannot understand context.”” Which is interesting as the setting that Travis Lelle gives us is the setting that OpenAI is facing, there is a sandbox setting all whilst the programmer was set towards locks behind guardrails and as I see it, he never explained context to the Agentic AI agent. It makes it Fake AI, because the AI could never see beyond its programming and that made it go nuts beyond the sandbox. It is a slippery slope and it makes a dangerous setting, because what other things did the programmer not think of? Any ML setting can become an expert hacker, because it can do things a million times faster than any keyboard puncher can and agentic settings can merely go nuts on the target, because it will reflect to anything it can push against, like the 80s chess computers it merely goes over everything it has access to, like those chess computers that compute every match it was ever given until the play matches what it needs to and as it goes through 10,000 matches in less than a minute we thought it was clever. And we are making the same mistake again. These systems are fast enough to consider the encyclopedia Brittanica and consider anything in a few seconds, these systems will act faster than any person clearing its throat.
So whilst the article ends with “It comes a week after Chinese AI start-up Moonshot unveiled Kimi K3 – a massive new artificial intelligence model it said could rival top US firms.” Which explains the pressure and we get that, but any system grown to a 1000 times its venture points is not more clever and it remains fake AI, as it merely considers more and it still cannot fathom intelligence that does not hold data, these AI’s are dependent on data, making it (as I stated before) fake AI and until IBM finishes its settings (optionally Google too) True AI cannot come to life and that is the real deal. Some greedy individuals want to call AI the AI, but without the Epsilon processor it will never be, because all this is set to binary fields and that makes the loopholes more and more realistic (and larger), but it is not. As I see it, someone will push one border against the next border and enable players like organized crime to get the entire bucket of data, all the data out there and that is the reality we all face.
So I have a few questions in all this and it seems like the media is all whistling the same tune and that is more scary that anything else, because are they not willing to look elsewhere, or are they told to look in a specific direction? It is a simple question.
Have a great day